机器之心 & ArXiv Weekly Radiostation
参与:杜伟、楚航、罗若天
本周的重要论文包括马克斯 · 普朗克智能系统研究所主任 Bernhard Sch?lkopf 以及 Bengio 等学者的因果表示学习综述,以及 OpenAI 文本生成图像模型 DALL·E 的官方论文。
Towards Causal Representation Learning
Transformer is All You Need: Multimodal Multitask Learning with a Unified Transformer
Adaptive Semiparametric Language Models?
Exploring Cross-Image Pixel Contrast for Semantic Segmentation?
Zero-Shot Text-to-Image Generation
Knowledge-Routed Visual Question Reasoning: Challenges for Deep Representation Embedding
Occluded Video Instance Segmentation
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Towards Causal Representation Learning摘要:马克斯 · 普朗克智能系统研究所主任、苏黎世联邦理工学院教授 Bernhard Sch?lkopf 以及 Yoshua Bengio 等研究者在这篇论文中回顾了因果推理的基础概念,并将其与机器学习的关键开放性问题联系起来,如迁移与泛化,进而分析因果推理可能对机器学习研究做出的贡献。反过来看也是如此:大多数因果研究的前提是因果变量。因此目前 AI 与因果领域的核心问题是因果表示学习,即基于低级观测值发现高级因果变量。最后,该论文描绘了因果对机器学习的影响,并提出了该交叉领域的核心研究方向。论文第二章介绍了物理系统中因果建模的不同层级,第三章展示了因果模型与统计模型的区别。这里不仅探讨了建模能力,还讨论了所涉及的假设与挑战。
论文第四章将独立因果机制(Independent Causal Mechanisms,ICM)原则扩展为基于数据估计因果关系的核心组件,即将稀疏机制转移(Sparse Mechanism Shift)假设作为 ICM 原则的结果,并探讨它对学习因果模型的影响。
论文第五章回顾了现有基于恰当描述子(或特征)学习因果关系的方法,覆盖经典方法和基于深度神经网络的现代方法,主要聚焦促成因果发现的底层原则。
论文第六章探讨了如何基于因果表示数据学习有用的模型,以及从因果角度看机器学习问题。
论文第七章分析了因果对实际机器学习的影响。研究者使用因果语言重新诠释了鲁棒性和泛化,以及半监督学习、自监督学习、数据增强和预训练等常见技术。研究者还探讨了因果与机器学习在科学应用中的交叉领域,并思考如何结合二者的优势,创建更通用的人工智能。
推荐:本论文介绍了深度学习后,图灵奖得主 Yoshua Bengio 的核心研究 - 因果表示学习。论文 2:Transformer is All You Need: Multimodal Multitask Learning with a Unified Transformer摘要:在本文中,来自 FAIR 的研究者提出了一个 Unified Transformer(UniT)模型,它可以同时学习不同领域的最重要任务,比如目标检测、语言理解和多模态推理。基于 Transformer 编码器 - 解码器架构,UniT 模型利用一个编码器编码每个输入模态,并利用一个共享解码器在每个任务上对解码后的输入表示进行预测,最后对特定于任务的输出头进行预测。整个模型通过每个任务的损失进行端到端地训练。与以往利用 transformer 的多任务学习不同,研究者在所有任务上共享相同的模型参数而不是单独微调的特定于任务的模型,并处理不同领域的更多样化的任务。在实验中,研究者在八个数据集上共同学习了七项任务,并在相同的监督下通过一组紧凑的模型参数,在每个领域均实现了媲美以往模型的性能。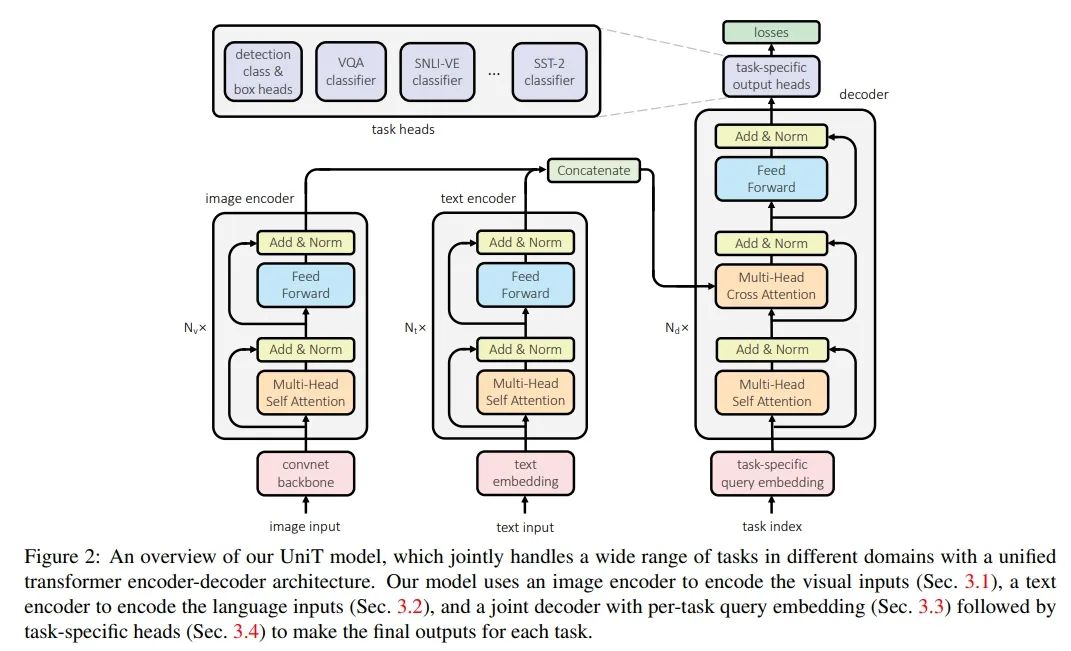
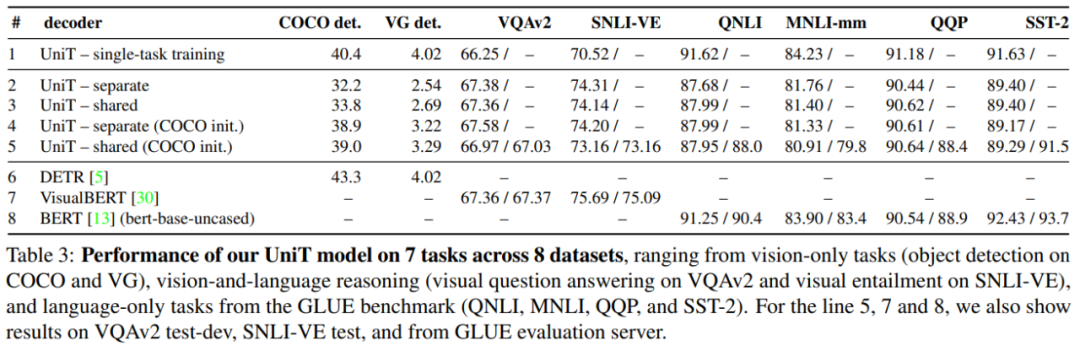
UniT 模型在 COCO det.、VG det. VQAv2、SNLI-VE、QNLI、MNLI-mm、QQP 和 SST-2 等八个数据集上七项任务的性能。
在八个数据集上 UniT 模型利用共享解码器的预测结果。
推荐:本文是 Transformer 跨界应用的又一尝试,研究者提出的 UniT 模型在目标检测、语言理解和多模态推理等多领域均实现了匹配以往模型的性能。这也许真正实现了「Transformer is all you need」。论文 3:Adaptive Semiparametric Language Models摘要:在本文中,来自 DeepMind 的研究者提出了一种能够在集成架构中结合大型参数神经网络(即 transformer)与非参数情境记忆组件的语言模型。该模型通过缓存局部隐藏状态(local hidden state)(其类似于 transformer-XL)使用扩展的短期上下文,并通过在每一时间步检索一组最近邻 token 使用全局长期记忆。研究者设计了一个门函数以自适应地结合多个信息源并做出预测。这种机制使得语言模型可以根据上下文来临时使用局部上下文、短期记忆、长期记忆或三者的任意组合。与强基准方法相比,研究者在基于单词和基于字符的语言建模数据集上验证了该方法的有效性。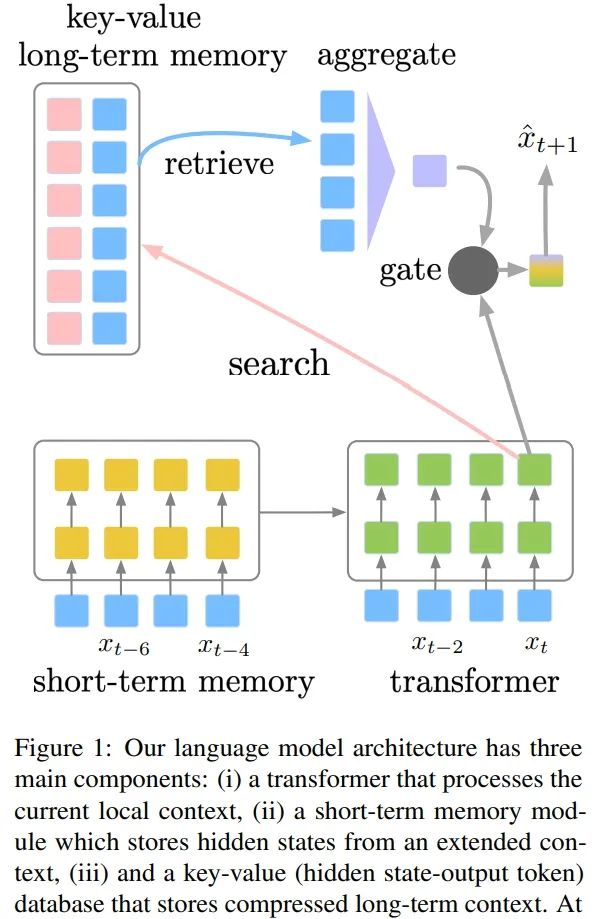
该研究提出的语言模型架构包含三个主要组件:处理当前局部上下文的 transformer、存储扩展上下文中隐藏状态的短期记忆、存储压缩长期上下文的键值(key-value)数据库。
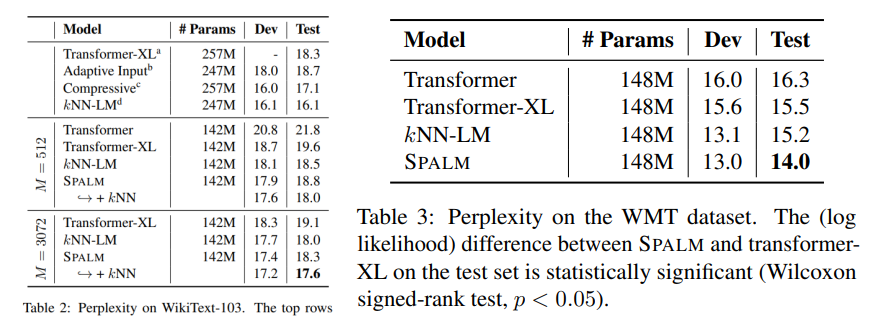
WikiText-103 和 WMT 数据集上的困惑度。
推荐:一种结合局部上下文、短(长)期记忆进行预测的自适应半参数语言模型。论文 4:Exploring Cross-Image Pixel Contrast for Semantic Segmentation?摘要:当前,语义分割算法的本质是通过深度神经网络将图像像素映射到一个高度非线性的特征空间。然而,现有算法大多只关注于局部上下文信息(单个图像内、像素之间的位置和语义依赖性),却忽略了训练数据集的全局上下文信息(跨图像的、像素之间的语义相关性),因而难以从整体的角度对习得的特征空间进行约束,进而限制了语义分割模型的性能。最近,苏黎世联邦理工学院及商汤研究院的研究者提出了一种新的、全监督语义分割训练范式:像素对比学习(pixel-wise contrastive learning),强调利用训练集中、跨图像的像素 - 像素对应关系(cross-image pixel-to-pixel relation)来学习一个结构化(well structured)的特征空间,用来替代传统的、基于图像的(image-wise)训练范式。该训练策略可直接应用于主流的语义分割模型,并在模型推理阶段不引入额外计算开销。下图展示了在 Cityscapes 验证集上主流分割算法的性能,可以看出,在 DeepLabV3、HRNet、OCR 上引入像素对比学习后,取得了较为显著的性能提升。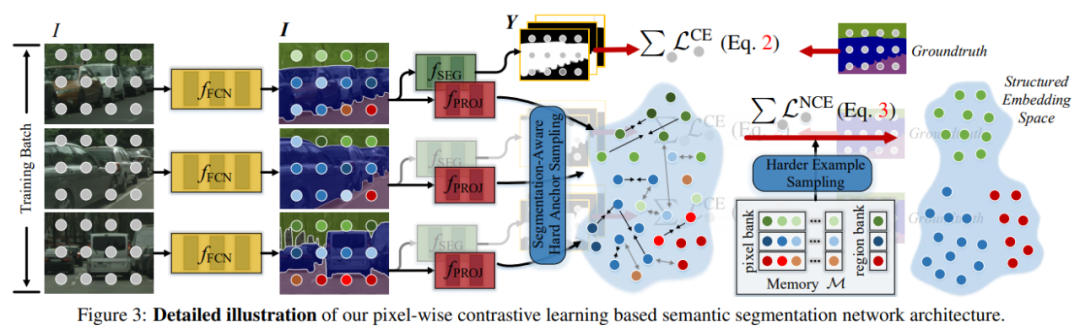

Cityscapes val 上不同对比机制、不同内存块(memory bank)设计和不同难例采样策略之间的对比结果。
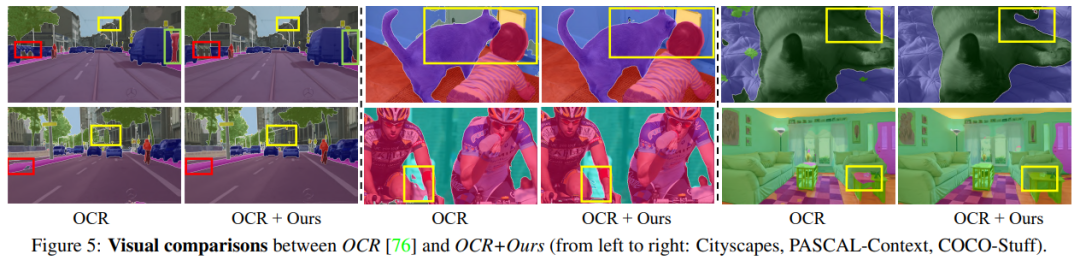
从左至右,在 Cityscapes、PASCAL-Context 和 COCO-Stuff 数据集上,OCR 和 OCR 结合本研究方法的视觉对比结果。
推荐:一种新的、全监督语义分割训练范式「像素对比学习」,可以用来替代传统的、基于图像的训练范式。论文 5:Zero-Shot Text-to-Image Generation摘要:传统上,文本到图像的生成主要集中在在固定的训练数据集上找到更好的建模假设。这些假设可能涉及复杂的体系架构、辅助损失或辅助信息,例如在训练期间提供的对象部件标签或分割掩码。因此,OpenAI 的研究者提出了一种基于 transformer 的简单方法,将文本和图像 token 作为单个数据流进行自回归建模。在足够数据和扩展的情况下,当以 zero-shot 方式评估时, 该研究提出的方法能够媲美以前领域特定的模型。
在不同信任度时,该研究提出的模型能够以合理的方式结合不同的概念,创建拟人化的动物形象,渲染文本,并执行一些类型的图像到图像转换。

在 MS-COCO 数据集中的数据标注(caption)上,该研究所提模型生成的样本与基于以往方法(如 AttnGAN、DM-GAN 等)生成的样本之间的对比。

在 MS-COCO 数据标注上,增加图像数量对对比重排序流程(contrastive reranking procedure)的影响。
推荐:1 月初,OpenAI 连放大招,推出了两个连接文本与图像的网络:DALL·E 和 CLIP,不过当时并没有同时放出论文和代码。近日,OpenAI 官方终于放出了 DALL·E 的论文和代码。论文 6:Knowledge-Routed Visual Question Reasoning: Challenges for Deep Representation Embedding摘要:近期,中山大学人机物智能融合实验室发布了基于常识的无偏视觉问答数据集 (Knowledge-Routed Visual Question Reasoning, KRVQA)。由于自然语言与标注者中自然存在的偏差,现有的算法能够通过拟合数据集内的这些偏差达到很好的效果,而不需要理解对应的文字和图像信息。相关论文发表在国际知名顶级期刊 TNNLS 上。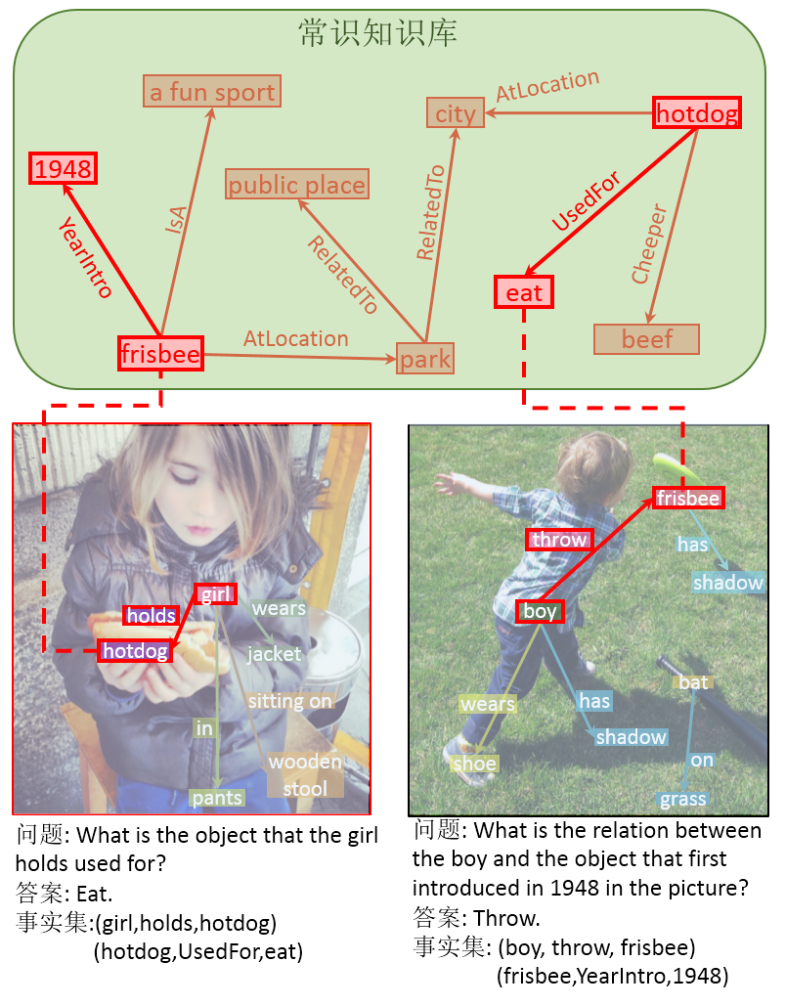


不同知识库编码方法与 MCAN 基线方法的准确率。
推荐:中山大学无偏视觉问答数据集 KRVQA 论文登上顶刊 TNNLS。论文 7:Occluded Video Instance Segmentation摘要:对于被遮挡的物体,人类能够根据时序上下文来识别,定位和追踪被遮挡的物体,甚至能脑补出物体被遮住的部分,那么现有的深度学习方法对遮挡场景的处理能力如何呢?为了探究这个问题,来自阿里、华中科大、牛津等多个机构的研究者构建了一个针对强遮挡场景的大型视频实例分割数据集 Occluded Video Instance Segmentation (OVIS)。视频实例分割 (Video Instance Segmentation, VIS) 要求算法能检测、分割、跟踪视频里的所有物体。与现有 VIS 数据集相比,OVIS 最主要的特点就是视频里存在大量的多种多样的遮挡。因此,OVIS 很适合用来衡量算法对于遮挡场景的处理能力。实验表明,现有方法并不能在强遮挡场景下取得令人满意的结果,相比于广泛使用的 YouTube-VIS 数据集,几乎所有算法在 OVIS 上的指标都下降了一半以上。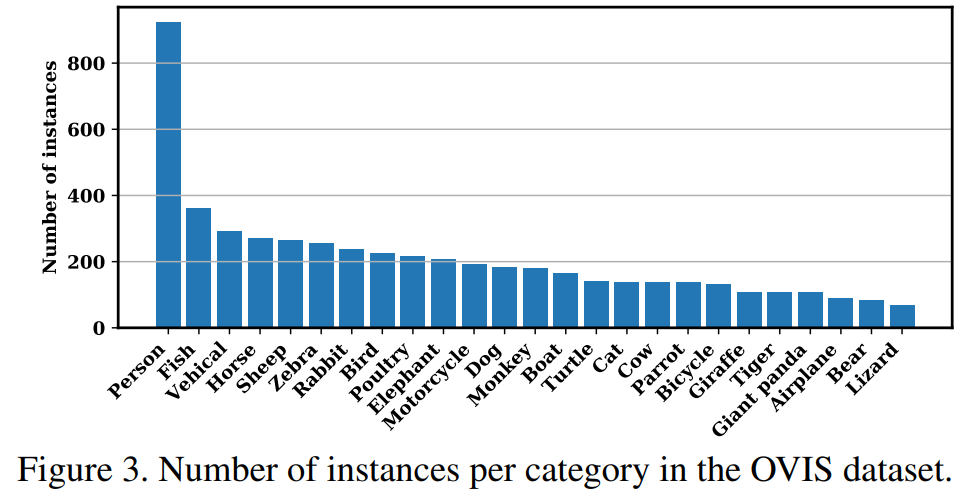
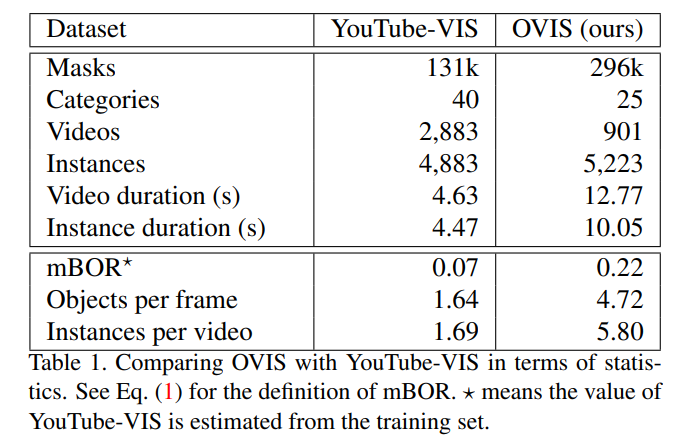
OVIS 与 YouTube-VIS 数据集的对比。
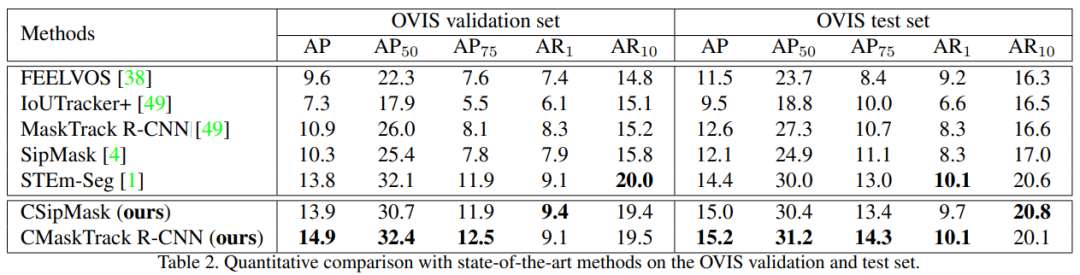
OVIS 验证和测试集上,CSipMask 和 CMaskTrack R-CNN 与 SOTA 方法的定量对比结果。
推荐:近千片段、25 种类别,阿里等开源了遮挡场景的视频实例分割数据集 OVIS。ArXiv Weekly Radiostation机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:1. Minimally-Supervised Structure-Rich Text Categorization via Learning on Text-Rich Networks.? (from Jiawei Han)2. The Sensitivity of Word Embeddings-based Author Detection Models to Semantic-preserving Adversarial Perturbations.? (from Quan Zhou)3. LazyFormer: Self Attention with Lazy Update.? (from Tie-Yan Liu)4. Automated Quality Assessment of Cognitive Behavioral Therapy Sessions Through Highly Contextualized Language Representations.? (from David C. Atkins)5. QNLP in Practice: Running Compositional Models of Meaning on a Quantum Computer.? (from Bob Coecke)6. MixSpeech: Data Augmentation for Low-resource Automatic Speech Recognition.? (from Tao Qin)7. Learning Dynamic BERT via Trainable Gate Variables and a Bi-modal Regularizer.? (from Nojun Kwak)8. Calibrate Before Use: Improving Few-Shot Performance of Language Models.? (from Sameer Singh)9. IIE-NLP-Eyas at SemEval-2021 Task 4: Enhancing PLM for ReCAM with Special Tokens, Re-Ranking, Siamese Encoders and Back Translation.? (from Wei Peng)10. Enhancing Model Robustness By Incorporating Adversarial Knowledge Into Semantic Representation.? (from Hui Xue)1. Zero-Shot Text-to-Image Generation.? (from Alec Radford, Ilya Sutskever)2. Object Detection in Aerial Images: A Large-Scale Benchmark and Challenges.? (from Xiang Bai, Serge Belongie, Jiebo Luo, Liangpei Zhang)3. STEP: Segmenting and Tracking Every Pixel.? (from Andreas Geiger, Bastian Leibe, Daniel Cremers, Liang-Chieh Chen)4. "Train one, Classify one, Teach one" -- Cross-surgery transfer learning for surgical step recognition.? (from Gregory D. Hager)5. Meta-Learned Attribute Self-Gating for Continual Generalized Zero-Shot Learning.? (from Lawrence Carin)6. IBRNet: Learning Multi-View Image-Based Rendering.? (from Noah Snavely, Thomas Funkhouser)7. Self-Taught Semi-Supervised Anomaly Detection on Upper Limb X-rays.? (from Jean-Philippe Thiran)8. Pose Guided Person Image Generation with Hidden p-Norm Regression.? (from Alexander G. Hauptmann)9. CelebA-Spoof Challenge 2020 on Face Anti-Spoofing: Methods and Results.? (from Jian Liu)10. Simple multi-dataset detection.? (from Vladlen Koltun)
本周 10?篇 ML 精选论文是:
1. Nonlinear Invariant Risk Minimization: A Causal Approach.? (from Bernhard Sch?lkopf)2. Efficient Distributed Auto-Differentiation.? (from Vince D. Calhoun)3. Understanding Catastrophic Forgetting and Remembering in Continual Learning with Optimal Relevance Mapping.? (from Alan Yuille)4. When is Early Classification of Time Series Meaningful?.? (from Eamonn J. Keogh)5. Constructing Evacuation Evolution Patterns and Decisions Using Mobile Device Location Data: A Case Study of Hurricane Irma.? (from Lei Zhang)6. Disentangling brain heterogeneity via semi-supervised deep-learning and MRI: dimensional representations of Alzheimer's Disease.? (from Christos Davatzikos)7. Training cascaded networks for speeded decisions using a temporal-difference loss.? (from Samy Bengio)8. Deterministic Neural Networks with Appropriate Inductive Biases Capture Epistemic and Aleatoric Uncertainty.? (from Philip H.S. Torr)9. Deep Latent Competition: Learning to Race Using Visual Control Policies in Latent Space.? (from Daniela Rus)10. Controllable and Diverse Text Generation in E-commerce.? (from Tarek Abdelzaher)关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/








 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




