云从科技语音组提出了一种基于 BART 预训练模型的语义纠错技术方案,它不仅可以对 ASR 数据中常见的拼写错误进行纠正,还可以对一些常识错误、语法错误,甚至一些需要推理的错误进行纠正。
近些年来,随着自动语音识别(ASR)技术的发展,识别准确率有了很大的提升。但是,在 ASR 转写结果中,仍然存在一些对人类来说非常明显的错误。我们并不需要听音频,仅通过观察转写的文本便可发现。对这类错误的纠正往往需要借助一些常识和语法知识,甚至推理的能力。得益于最近无监督预训练语言模型技术的发展,基于纯文本特征的纠错模型可以有效地解决这类问题。本文提出的语义纠错系统分编码器和解码器两个模块,编码器着重于理解 ASR 系统输出文本的语义,解码器的设计重在使用规范的词汇重新表达。
论文链接:https://arxiv.org/abs/2104.05507文本纠错是一项提升 ASR 识别准确率的重要方法,常见的文本纠错有语法纠错,拼写纠错等。由于 ASR 系统转写的错误分布与上述的错误分布差异较大,所以这些模型往往并不适合直接用在 ASR 系统中。这里,云从科技语音组提出了一种基于 BART 预训练模型 [1] 的语义纠错(SC)技术方案,它不仅可以对 ASR 数据中常见的拼写错误进行纠正,还可以对一些常识错误、语法错误,甚至一些需要推理的错误进行纠正。在我们一万小时数据的实验中,纠错模型可以将基于 3gram 解码结果的错字率(CER)相对降低 21.7%,取得与 RNN 重打分相近的效果。在 RNN 重打分的基础上使用纠错,可以进一步取得 6.1% 的 CER 相对降低。误差分析结果表明,实际纠错的效果比 CER 指标显示的要更好。ASR 语义纠错流程如图 1 所示。语义纠错模块可以直接应用在第一遍解码结果上,作为重打分模块的替代方案。另外,它也可以接在重打分模型之后,进一步提升识别准确率。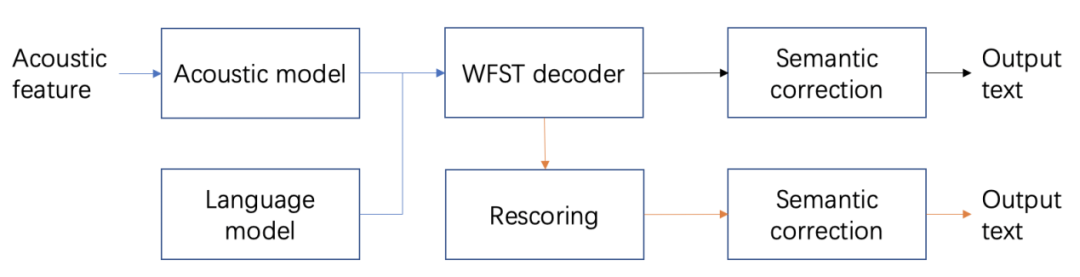
作者选取的 baseline 声学模型结构为 pyramidal FSMN[2],在 1 万小时普通话音频数据上训练。在第一遍解码中使用的 WFST 由 3gram 语言模型,发音词典,双音素结构以及 HMM 结构构成。在重打分中分别使用 4gram 和 RNN,训练数据为这些音频对应的参考文本。声学模型和语言模型使用 Kaldi 工具 [3] 训练。研究者提出的语义纠错模型基于 Transformer [4]结构,它包含 6 层 encoder layer 和 6 层 decoder layer,建模单位为 token。在使用 Teacher forcing 方法训练过程中,ASR 输出的文本输入到模型的输入侧,对应的参考文本输入到模型的输出侧,分别使用输入嵌入矩阵和输出嵌入矩阵进行编码,使用交叉熵作为损失函数。在语义纠错模型推理过程中使用束搜索(beam search)进行解码,beam 宽度设置为 3。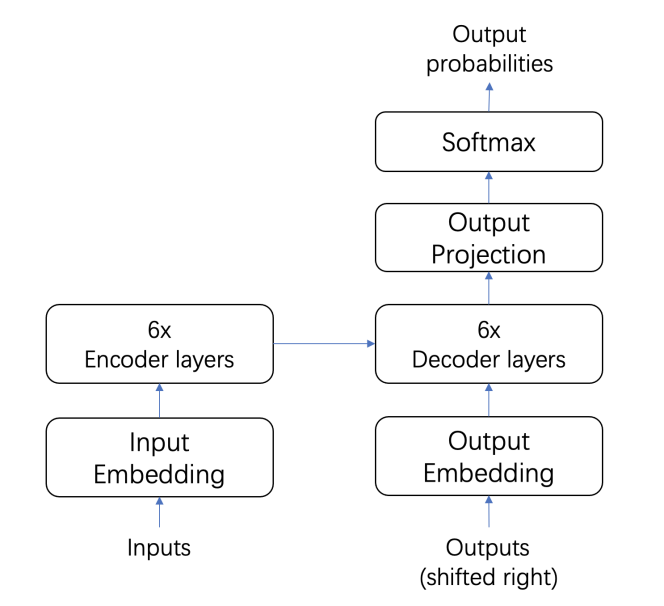
Figure 2 基于 Transformer 的语义纠错模型我们基线 ASR 模型的训练集为 1 万小时普通话语音数据,包含约 800 条转写文本。侧试集由 5 小时混合语音数据组成,包含 Aishell, Thchs30 等侧试集。为了对 ASR 系统识别的错误分布充分采样,我们在构建纠错模型训练数据集时采用了以下几个技巧:使用弱声学模型生成纠错训练数据,这里采用 10% 的语音数据单独训练一个小的声学模型,用于生成训练数据;
对 MFCC 特征增加扰动,将 MFCC 特征随机乘上一个 0.8 到 1.2 之间的系数;
将带噪声的特征输入到弱声学模型,取 beam search 前 20 条结果,并根据错字率阈值筛选样本。最后,我们将筛选后的解码结果和他们对应的参考文本配对,作为纠错模型训练数据。通过对全量音频数据解码,将阈值设置在 0.3,我们获得了约 3 千万纠错样本对。
在语义纠错模型中,输入和输出的文本使用相同词典。但是输入文本中的错字相对于其规范的用法蕴含更多的语义,而输出文本中仅使用规范的字词进行表达。因此,将输入和输出侧的 token 采用独立的表示,更符合纠错任务的需求。表一的结果证明了我们的这个推论。实验结果表明在输入输出嵌入矩阵共享权重时,纠错模型会带来负面效果。当输入输出 token 采用独立的表示时,系统的 CER 可以取得 5.01% 的相对降低。
这里,研究者预训练语言模型技术,将它从大规模语料中学习到的语义知识迁移到纠错场景中,使得纠错模型在相对较小的训练集上获得较好的鲁棒性和泛化性。我们对比随机初始化,BERT[5]初始化和 BART[1]初始化方法。在初始化过程中,因为 BART 预训练任务和模型结构于 Transformer 相同,因此参数可以直接复用。在 BERT 初始化中,Transformer 的编码器和解码器都适用 BERT 的前 6 层网络参数[6]。
表二结果显示 BART 初始化可以将基线 ASR 的错字率降低 21.7%,但是 BERT 初始化的模型相对随机初始化模型的提升非常有限。我们推侧这可能是因为 BERT 和语义纠错模型的结构以及训练目标差异过大,知识没有得到有效地迁移。此外,纠错模型对于语言模型重打分后的输出再进行纠正,识别率可以获得进一步提升。相对 4gram,RNN 重打分之后的结果,CER 可以分别相对降低 21.1% 和 6.1%。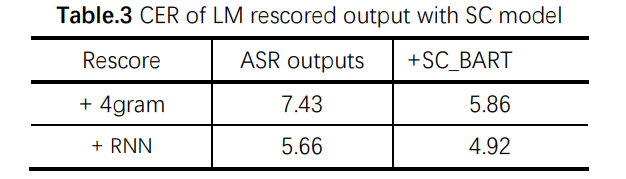
一般而言,ASR 系统使用更大的语言模型可以获得更好的识别效果,但也会消耗更多的内存资源并降低解码效率。这里,我们在语音数据参考文本的基础上,加入大量爬虫或者开源的纯文本语料,新训练 3gram, 4gram 和 RNN 语言模型,并称之为大语言模型。基线 ASR 系统中使用的称为为小模型。对比发现,在小模型基础上加上纠错的识别准确率超越了单独使用大模型的效果。另外,在大模型的基础上使用语义纠错,识别率可以获得进一步提升。

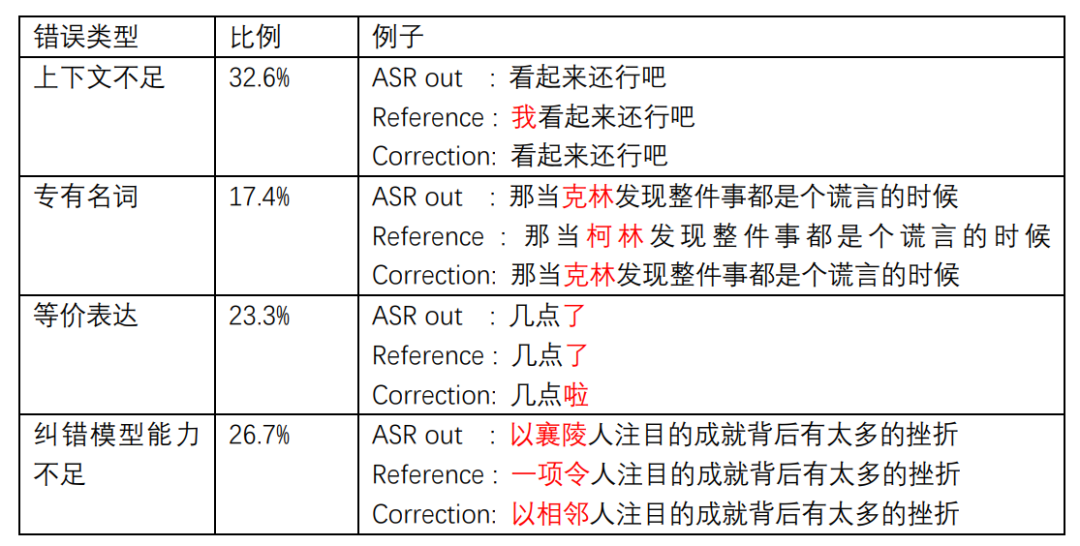
在对 300 条纠正失败的例子进行误差分析时,我们发现语义纠错实际效果要比 CER 指标评估的明显要好,有约 40% 的错误几乎不影响语义,比如,一些音译的外国人名或者地名有多种表达方式,一些人称代词因为缺乏上下文,会造成“她他它“的混用,还有一些是不影响语义的语气词替换。另外有 30% 的错误因为上下文信息不足,不适合基于纯文本特征的模型做纠正。剩下有 30% 的错误为语义纠错模型的语义理解或表达能力不足所致。本文提出了一种基于 BART 的语义纠错模型,它具有良好的泛化性,对多种 ASR 系统的识别结果有一致性地提升。另外,研究者通过实验验证了在文本纠错任务中,输入输出采用独立表示的重要性。为了更充分地对 ASR 系统识别错误分布进行采样,本文提出了一种简单有效的纠错数据生成策略。最后,我们提出的语义纠错方法虽然取得了一定收益,但还有可以优化的空间,比如:1,引入声学特征,有助于模型辨识文本是否存在错误,降低误触率。2,引入更多上下文信息,可以消除文本中一些语义上的歧义或者缺失的信息。3,针对垂直业务场景进行适配,提升一些专业术语的识别准确率。[1]M. Lewis et al., “BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension,” 2019, [Online]. Available: http://arxiv.org/abs/1910.13461.[2]X. Yang, J. Li, and X. Zhou, “A novel pyramidal-FSMN architecture with lattice-free MMI for speech recognition,” vol. 1, Oct. 2018, [Online]. Available: http://arxiv.org/abs/1810.11352.[3]D. Povey et al., “The Kaldi Speech Recognition Toolkit,” IEEE Signal Process. Soc., vol. 35, no. 4, p. 140, 2011.[4]A. Vaswani et al., “Attention Is All You Need,” Jun. 2017, doi: 10.1017/S0140525X16001837.[5]J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” 2018, [Online]. Available: http://arxiv.org/abs/1810.04805.[6]O. Hrinchuk, M. Popova, and B. Ginsburg, “Correction of Automatic Speech Recognition with Transformer Sequence-to-sequence Model,” ICASSP 2020 - 2020 IEEE Int. Conf. Acoust. Speech Signal Process., pp. 7074–7078, Oct. 2019, [Online]. Available: http://arxiv.org/abs/1910.10697.建新·见智 —— 2021亚马逊云科技 AI 在线大会
4月22日 14:00 - 18:00
为什么有那么多的机器学习负载选择亚马逊云科技?大规模机器学习、企业数字化转型如何实现?
《建新 · 见智——2021 亚马逊云科技 AI 在线大会》由亚马逊云科技全球人工智能技术副总裁及杰出科学家 Alex Smola、亚马逊云科技大中华区产品部总经理顾凡领衔,40多位重磅嘉宾将在主题演讲及6大分会场上为你深度剖析亚马逊云科技创新文化,揭秘 AI/ML 如何帮助企业加速创新。
分会场一:亚马逊机器学习实践揭秘
分会场二:人工智能赋能企业数字化转型
分会场三:大规模机器学习实现之道
分会场四:AI 服务助力互联网快速创新
分会场五:开源开放与前沿趋
分会场六:合作共赢的智能生态
6大分会场,你对哪个主题更感兴趣?
识别二维码或点击阅读原文,免费报名看直播。

??THE END?
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号





