机器之心 & ArXiv Weekly Radiostation参与:杜伟、楚航、罗若天
本周的重要论文包括?UC 伯克利等机构的研究者使用一种名为 PlenOctrees 的数据结构;微软亚研的研究者提出的通过移动窗口(shifted windows)计算的分层视觉 Transformer;北京大学、中山大学、微软亚研等机构的研究者提出的 Seeing Out of tHe bOx(SOHO)的概念,实现中文翻译即「开箱即看」等。
BART based semantic correction for Mandarin automatic speech recognition system
PlenOctrees for Real-time Rendering of Neural Radiance Fields??
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows?
MobileStyleGAN: A Lightweight Convolutional Neural Network for High-Fidelity Image Synthesis
Convolutional Neural Opacity Radiance Fields
Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning
Self-supervised Video Representation Learning by Context and Motion Decoupling
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:BART based semantic correction for Mandarin automatic speech recognition system摘要:近些年来,随着自动语音识别(ASR)技术的发展,识别准确率有了很大的提升。但是,在 ASR 转写结果中,仍然存在一些对人类来说非常明显的错误。我们并不需要听音频,仅通过观察转写的文本便可发现。对这类错误的纠正往往需要借助一些常识和语法知识,甚至推理的能力。得益于最近无监督预训练语言模型技术的发展,基于纯文本特征的纠错模型可以有效地解决这类问题。本文提出的语义纠错系统分编码器和解码器两个模块,编码器着重于理解 ASR 系统输出文本的语义,解码器的设计重在使用规范的词汇重新表达。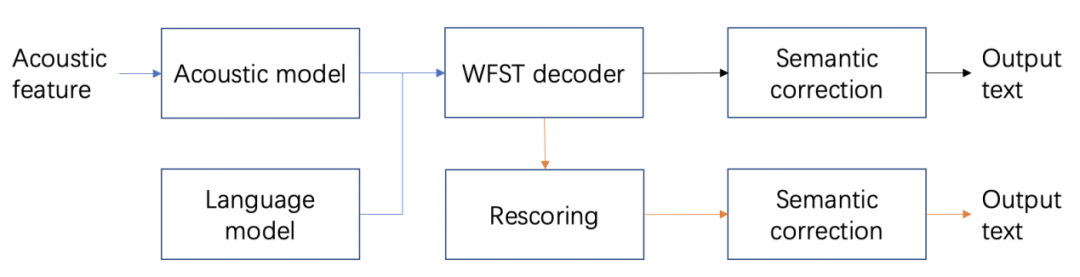
推荐:拼写、常识、语法、推理错误都能纠正,云从提出基于 BART 的语义纠错方法。论文 2:PlenOctrees for Real-time Rendering of Neural Radiance Fields摘要:从稀疏的静态图像合成任意 3D 视角物体和场景新视图是很多 VR 和 AR 应用的基础。近年来神经辐射场(Neural Radiance Fields, NeRF)的神经网络渲染研究通过神经网络编码实现了真实的 3D 视角场景渲染。但是 NeRF 需要极端的采样要求和大量的神经网络运算,导致其渲染速度十分缓慢,严重制约了其在实际场景,尤其是实时交互场景中的应用。例如,使用 NeRF 在高端 GPU 上渲染一张 800X800 像素的图片大概需要 30 秒。近日,来自 UC 伯克利等机构的研究者使用一种名为 PlenOctrees 的数据结构为 NeRF 引入了一种新的数据表示,实现了实时的 NeRF 渲染。其渲染速度比原始的 NeRF 提高了 3000 多倍,并且图像质量可以与 NeRF 媲美。采用 PlenOctrees 结构还能有效减少 NeRF 的训练时间。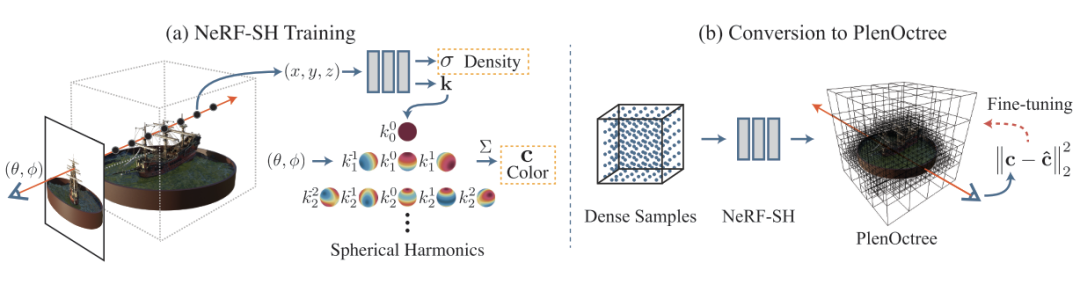
推荐:实时高保真渲染,基于 PlenOctrees 的 NeRF 渲染速度提升 3000 倍。论文 3:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows摘要:自 2017 年 6 月谷歌提出 Transformer 以来,它便逐渐成为了自然语言处理领域的主流模型。最近一段时间,Transformer 更是开启了自己的跨界之旅,开始在计算机视觉领域大展身手,涌现出了多个基于 Transformer 的新模型,如谷歌用于图像分类的 ViT 以及复旦、牛津、腾讯等机构的 SETR 等。由此,「Transformer 是万能的吗?」也一度成为机器学习社区的热门话题。不久前,微软亚研的研究者提出了一种通过移动窗口(shifted windows)计算的分层视觉 Transformer,他们称之为 Swin Transformer。相比之前的 ViT 模型,Swin Transformer 做出了以下两点改进:其一,引入 CNN 中常用的层次化构建方式构建分层 Transformer;其二,引入局部性(locality)思想,对无重合的窗口区域内进行自注意力计算。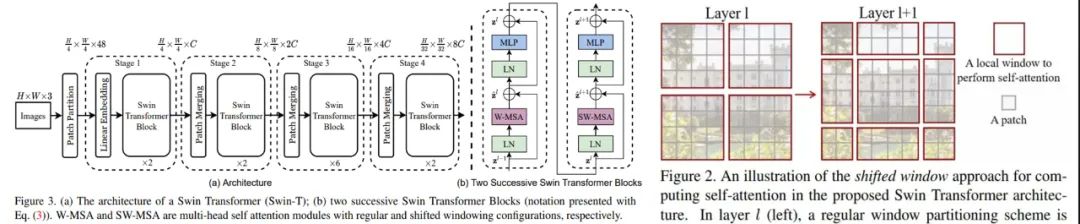
Swin Transformer 架构图(左),移动窗口示意图(右)。
推荐:霸榜多个 CV 任务,开源仅两天,微软分层 ViT 模型收获 2k star。论文 4:MobileStyleGAN: A Lightweight Convolutional Neural Network for High-Fidelity Image Synthesis摘要:近年来在生成图像建模中,生成对抗网络(GAN)的应用越来越多。基于样式(style-based)的 GAN 可以生成不同层次的细节,大到头部形状、小到眼睛颜色,它在高保真图像合成方面实现了 SOTA,但其生成过程的计算复杂度却非常高,难以应用于智能手机等移动设备。近日,一项专注于基于样式的生成模型的性能优化的研究引发了大家的关注。该研究分析了 StyleGAN2 中最困难的计算部分,并对生成器网络提出了更改,使得在边缘设备中部署基于样式的生成网络成为可能。该研究提出了一种名为 MobileStyleGAN 的新架构。相比于 StyleGAN2,该架构的参数量减少了约 71%,计算复杂度降低约 90%,并且生成质量几乎没有下降。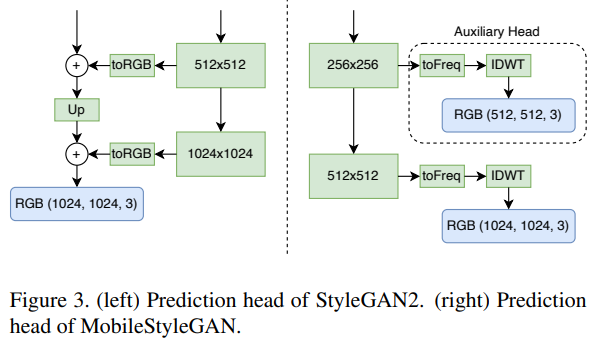
StyleGAN2 和 MobileStyleGAN 的预测头区别。
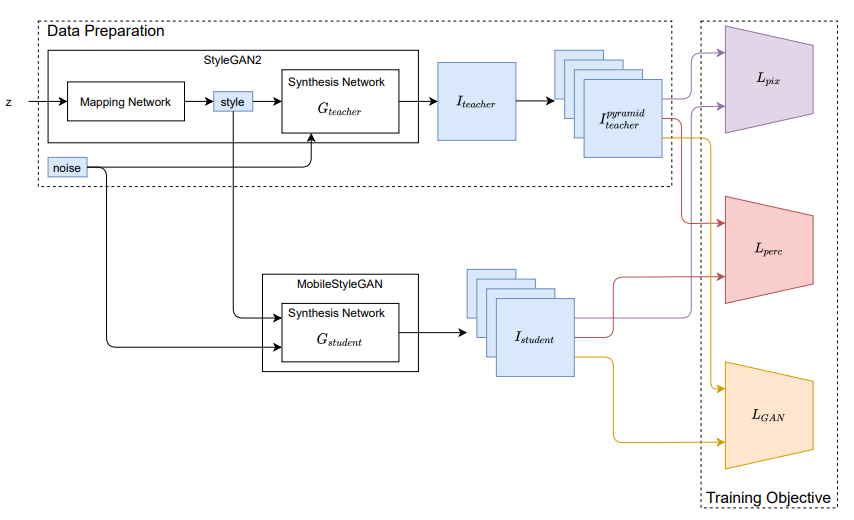
推荐:合成高保真图像,参数量、计算复杂度显著降低,压缩版 StyleGAN 或可在移动端部署。论文 5:Convolutional Neural Opacity Radiance Fields摘要:模糊复杂目标的高真实感建模和渲染对于许多沉浸式 VR/AR 应用至关重要,其中物体的亮度与颜色和视图强相关。本篇论文的研究者提出了一种有效的采样策略以及摄像机光线和图像平面,从而能够进行有效的辐射场采样,并以 patch-wise 的方式学习。同时,该研究还提出了一种新型的体积特征集成方案,该方案会生成 per-patch 混合特征嵌入,以重建视图一致的精细外观和不透明输出。此外,该研究进一步采用 patch-wise 对抗训练方案,以在自监督的框架中同时保留高频外观和不透明细节。该研究还提出了一种高效的多视图图像捕获系统,以捕获挑战性模糊目标的高质量色彩和 alpha 图。在现有数据集和新的含有挑战性模糊目标的数据集上进行的大量实验表明,该研究提出的新方法可以对多种模糊目标实现高真实感、全局一致、外观精细的不透明自由视角渲染。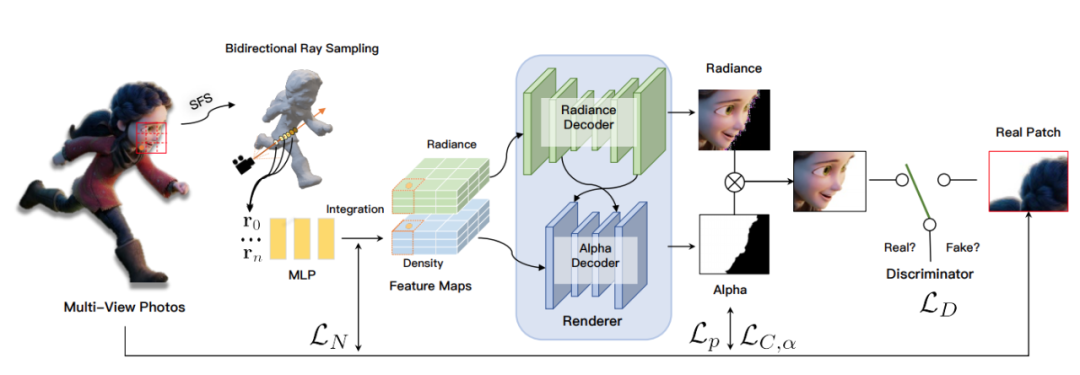
端到端 ConvNeRF pipeline 概览。
推荐:首个将显式不透明监督和卷积机制结合到神经辐射场框架中的方案。论文 6:Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning摘要:图像 - 文本检索中通常都是先抽取出图像中的显著区域,再与文字一一对齐。但是,由于基于区域的视觉特征只代表图像的一部分,因此现有视觉语言模型在充分理解配对自然语言的语义方面面临挑战。本文中,北京大学、中山大学、微软亚研等机构的研究者提出了 Seeing Out of tHe bOx(SOHO)的概念,中文翻译即「开箱即看」,它以完整的图像作为输入,并通过端到端的方式学习视觉语言表达。SOHO 最大的亮点是不需要边界框标注,从而使得推理速度比基于区域的方法提升了 10 倍。一系列实验也验证了 SOHO 的有效性。本文已被 CPVR 2021 会议接收。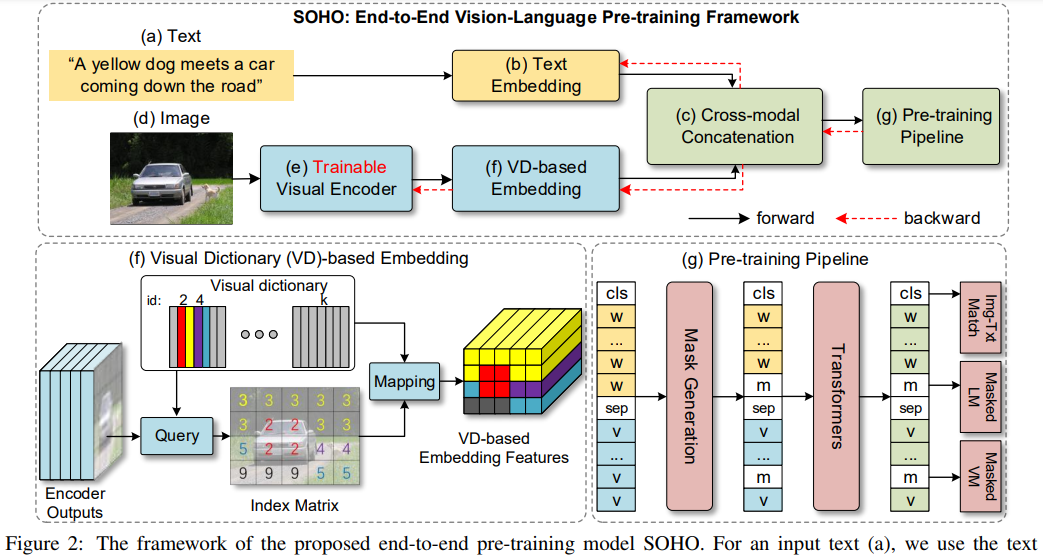
推荐:不需要边界框标注、用于视觉语言表征学习的端到端预训练模型 SOHO。论文 7:Self-supervised Video Representation Learning by Context and Motion Decoupling摘要:视频行为理解中的一个核心难点是「场景偏差」问题。比如,一段在篮球场跳舞的视频会被识别为打篮球,而非跳舞。在本文中,来自阿里巴巴机器智能技术实验室的研究者提出一种自监督视频表征学习方案,通过直接在代理任务中显式解耦场景与运动信息,处理「场景偏差」难题。基于该解耦方案预训练的视频网络模型可以迁移至行为理解和视频检索两项下游任务,性能均显著超越 SOTA。通过本文已被 CVPR 2021 会议接收。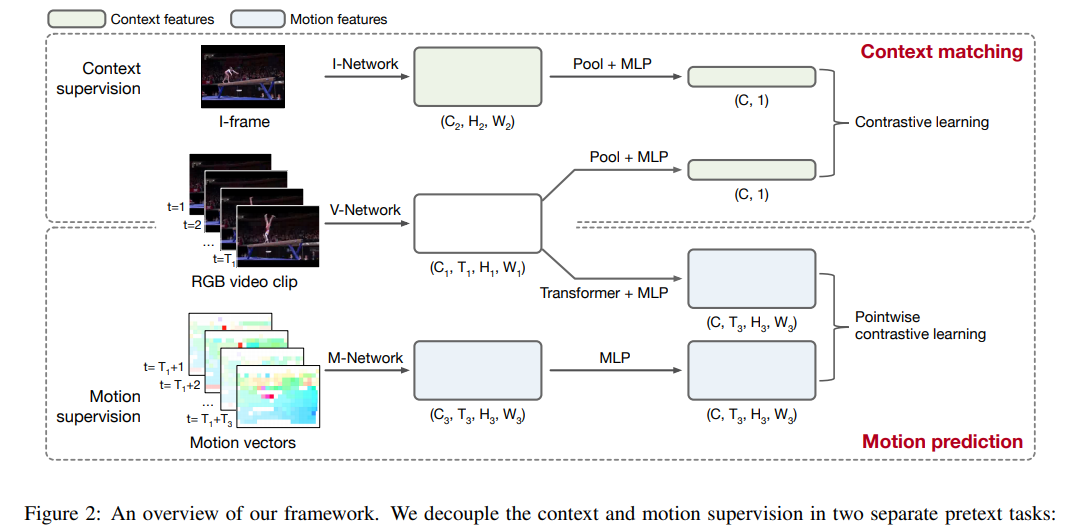
ArXiv Weekly Radiostation机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. Document-Level Event Argument Extraction by Conditional Generation.? (from Jiawei Han)2. Retrieval Augmentation Reduces Hallucination in Conversation.? (from Jason Weston)3. Equivalence of Segmental and Neural Transducer Modeling: A Proof of Concept.? (from Hermann Ney)4. QA-GNN: Reasoning with Language Models and Knowledge Graphs for Question Answering.? (from Jure Leskovec)5. Know What and Know Where: An Object-and-Room Informed Sequential BERT for Indoor Vision-Language Navigation.? (from Ming-Hsuan Yang, Anton van den Hengel)6. Efficient Large-Scale Language Model Training on GPU Clusters.? (from Matei Zaharia)7. Bridging the Gap Between Clean Data Training and Real-World Inference for Spoken Language Understanding.? (from Dacheng Tao)8. From partners to populations: A hierarchical Bayesian account of coordination and convention.? (from Thomas L. Griffiths, Noah D. Goodman)9. Family of Origin and Family of Choice: Massively Parallel Lexiconized Iterative Pretraining for Severely Low Resource Machine Translation.? (from Alex Waibel)10. NAREOR: The Narrative Reordering Problem.? (from Eduard Hovy)
1. Self-supervised Video Object Segmentation by Motion Grouping.? (from Andrew Zisserman)2. Points as Queries: Weakly Semi-supervised Object Detection by Points.? (from Xiangyu Zhang, Jian Sun)3. IQDet: Instance-wise Quality Distribution Sampling for Object Detection.? (from Jian Sun)4. NewsCLIPpings: Automatic Generation of Out-of-Context Multimodal Media.? (from Trevor Darrell)5. DexYCB: A Benchmark for Capturing Hand Grasping of Objects.? (from Jan Kautz, Dieter Fox)6. BARF: Bundle-Adjusting Neural Radiance Fields.? (from Antonio Torralba)7. DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort.? (from Antonio Torralba)8. Semantic Segmentation with Generative Models: Semi-Supervised Learning and Strong Out-of-Domain Generalization.? (from Antonio Torralba)9. One Ring to Rule Them All: a simple solution to multi-view 3D-Reconstruction of shapes with unknown BRDF via a small Recurrent ResNet.? (from Richard Hartley)10. GANcraft: Unsupervised 3D Neural Rendering of Minecraft Worlds.? (from Serge Belongie)本周 10?篇 ML 精选论文是:
1. Exact and Approximate Hierarchical Clustering Using A*.? (from Kyle Cranmer, Andrew McCallum)2. Deep Data Density Estimation through Donsker-Varadhan Representation.? (from Panos M. Pardalos)3. Relating Adversarially Robust Generalization to Flat Minima.? (from Bernt Schiele)4. Reducing Representation Drift in Online Continual Learning.? (from Tinne Tuytelaars, Joelle Pineau)5. Rehearsal revealed: The limits and merits of revisiting samples in continual learning.? (from Tinne Tuytelaars)6. Active learning for medical code assignment.? (from Evangelos Milios)7. Improved Branch and Bound for Neural Network Verification via Lagrangian Decomposition.? (from Pushmeet Kohli, Philip H.S. Torr)8. Online and Offline Reinforcement Learning by Planning with a Learned Model.? (from David Silver)9. Learning and Planning in Complex Action Spaces.? (from David Silver)10. Muesli: Combining Improvements in Policy Optimization.? (from Arthur Guez, Laurent Sifre, David Silver)??THE END?
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/







 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




