机器之心 & ArXiv Weekly Radiostation参与:杜伟、楚航、罗若天
本周的重要论文包括来自谷歌大脑的研究团队提出了一种舍弃卷积和自注意力且完全使用多层感知机(MLP)的视觉网络架构,在 ImageNet 数据集上实现了媲美 CNN 和 ViT 的性能表现;清华大学图形学实验室 Jittor 团队提出了一种新的注意机制,通过控制记忆单元的大小,External-attention 可以轻松实现线性的复杂度等研究。
MLP-Mixer: An all-MLP Architecture for Vision
Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks
Learning Skeletal Articulations with Neural Blend Shapes?
A Survey of Modern Deep Learning based Object Detection Models
Total Relighting: Learning to Relight Portraits for Background Replacement?
Graph Learning: A Survey
Locate then Segment: A Strong Pipeline for Referring Image Segmentation
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:MLP-Mixer: An all-MLP Architecture for Vision摘要:计算机视觉的发展史证明,规模更大的数据集加上更强的计算能力往往能够促成范式转变。虽然卷积神经网络已经成为计算机视觉领域的标准,但最近一段时间,基于自注意力层的替代方法 Vision Transformer(ViT)实现新的 SOTA 性能。从技术上讲,ViT 模型延续了长久以来去除模型中手工构建特征和归纳偏置的趋势,并进一步依赖基于原始数据的学习。近日,原 ViT 团队提出了一种不使用卷积或自注意力的 MLP-Mixer 架构(简称 Mixer),这是一种颇具竞争力并且在概念和技术上都非常简单的替代方案。Mixer 架构完全基于在空间位置或特征通道重复利用的多层感知机(MLP),并且仅依赖于基础矩阵乘法运算、数据布局变换(如 reshape 和 transposition)和非线性层。

JAX/Flax 编写的 MLP-Mixer 代码。推荐:CV 领域网络架构的演变从 MLP 到 CNN 到 Transformer 再回到 MLP,真是太有意思了。论文 2:Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks摘要:清华大学图形学实验室 Jittor 团队提出了一种新的注意机制,称之为「External Attention」,基于两个外部的、小的、可学习的和共享的存储器,只用两个级联的线性层和归一化层就可以取代了现有流行的学习架构中的「Self-attention」,揭示了线性层和注意力机制之间的关系。自注意力机制一个明显的缺陷在于计算量非常大,存在一定的计算冗余。通过控制记忆单元的大小,External-attention 可以轻松实现线性的复杂度。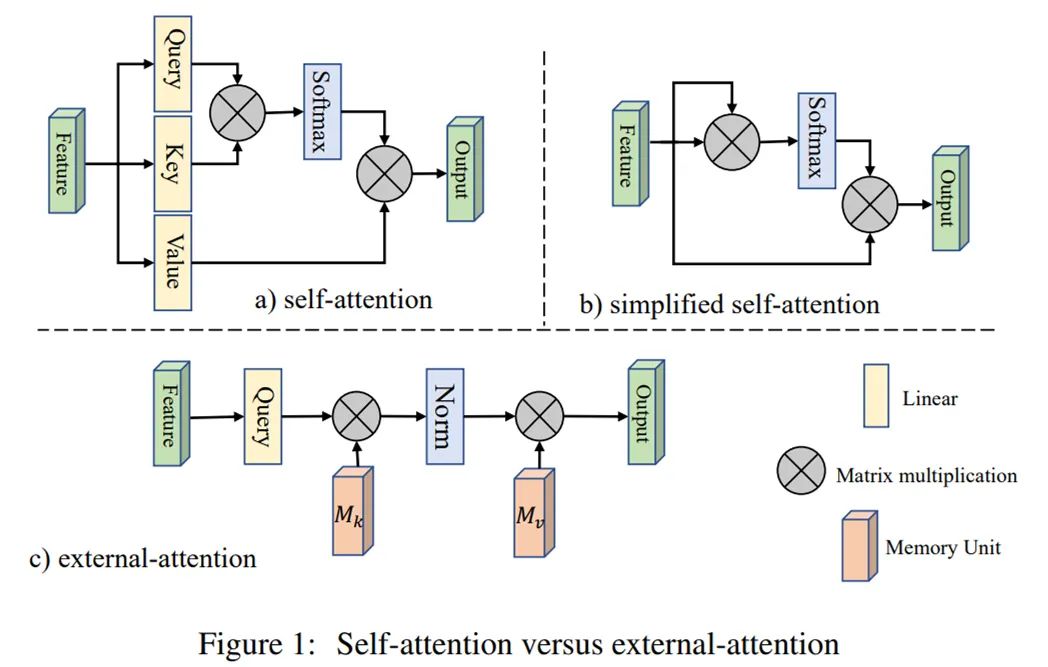
Self Attention 和 External Attention 的区别。
推荐:External Attention 的部分计图代码已经在 Github 开源,后续将尽快开源全部计图代码。论文 3:Learning Skeletal Articulations with Neural Blend Shapes摘要:该论文由北京大学陈宝权教授研究团队、北京电影学院未来影像高精尖创新中心、Google Research、特拉维夫大学以及苏黎世联邦理工学院合作,针对骨骼驱动的模型动画的高质量自动化生成进行改进,提出了神经融合形状技术。实验证明,该方法显著减少了已有方法中需要的人工干预,大大提升了生成动画的质量。具体而言,为了简化骨骼搭建和蒙皮权重绑定的过程、高效利用动作捕捉数据以及生成高质量的动画,研究者开发了一套能生成具有指定结构的骨骼以及精准绑定权重的神经网络。加以他们提出的神经融合形状(neural blend shapes)技术,研究者实现了实时高质量三维人物模型动画的端到端自动生成。

推荐:该论文已被计算机图形学顶级会议 SIGGRAPH 2021 接收。论文 4:A Survey of Modern Deep Learning based Object Detection Models摘要:在本文中,来自阿斯隆理工学院的研究者概述了基于深度学习的目标检测器的最新发展,提供了用于检测的基准数据集和评估指标的简要概述以及用于识别任务的主要主干架构。
文章结构。
推荐:基于现代深度学习的目标检测模型综述。
论文 5:Total Relighting: Learning to Relight Portraits for Background Replacement摘要:在人像抠图中,前景预测背景替换是至关重要的组成部分,此前也出现过各种效果不错的抠图方法,如商汤等提出的只需单张图像、单个模型的方法 MODNet、华盛顿大学单块 GPU 实现 4K 分辨率每秒 30 帧的 Background Matting 2.0 等。这些方法或多或少都有其局限性。近日,来自谷歌的几位研究者提出了一种全新的人像重照明(portrait relighting)和背景替换系统,该系统不仅保留了高频边界细节,并精确地合成了目标人像在新照明下的外观,从而为任何所需场景生成逼真的合成图像。该研究的亮点是通过前景蒙版(alpha matting)、重照明(relighting)和合成(compositing)进行前景估计。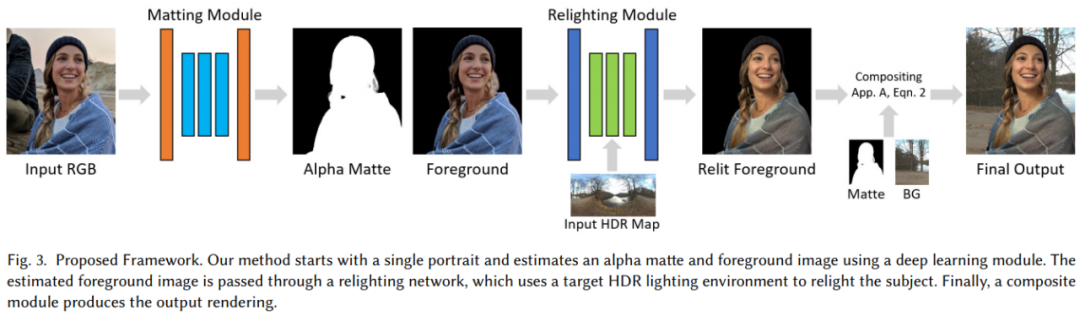

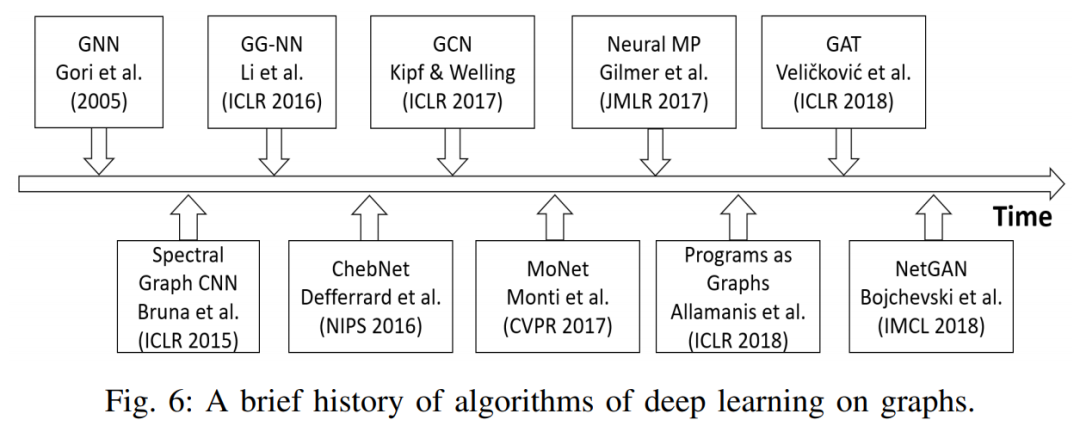
推荐:该论文已被 SIGGRAPH 2021 会议接收。论文 6:Graph Learning: A Survey摘要:本文是对图学习的最全面综述,重点关注四类已有的图学习方法,包括图信号处理、矩阵分解、随机游走和深度学习,回顾了采用这四类方法的主要模型和算法。此外,研究者探讨了文本、图像、科学、知识图谱和组合优化等领域的图学习应用。本文作者来自澳大利亚联邦大学、大连理工、莫纳什大学和亚利桑那州立大学。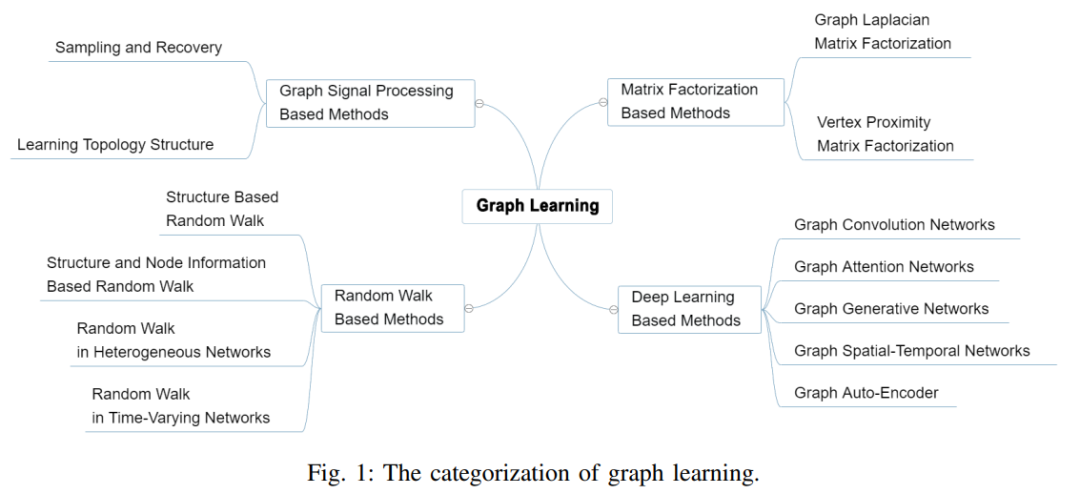
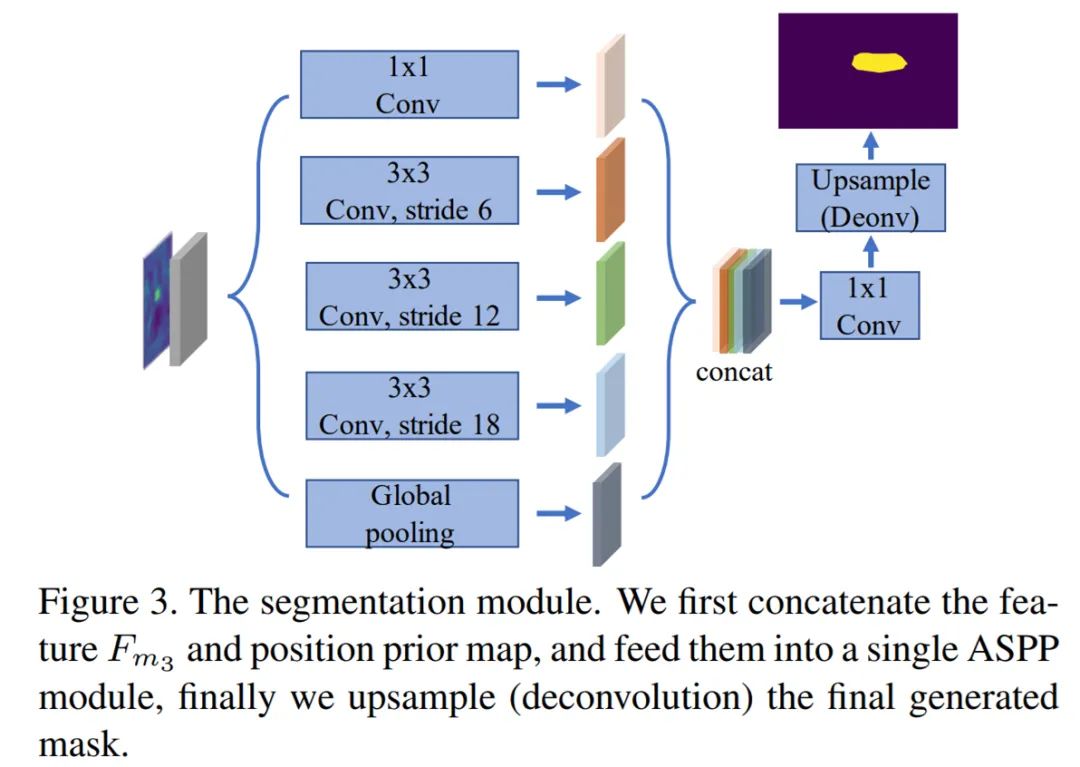
论文 7:Locate then Segment: A Strong Pipeline for Referring Image Segmentation摘要:如何通过自然语言定位并分割出场景中的目标物体?比如给定一张图片,语言指示 「分割出穿白色衬衫的人」。这个任务在学术界叫做指代性物体分割(Referring Image Segmentation)。目前指代性分割的工作通常着重于设计一种隐式的递归特征交互机制用于融合视觉 - 语言特征来直接生成最终的分割结果,而没有显式建模被指代物体的位置。为了强调语言描述的指代作用,来自中科院自动化所、字节跳动的研究者将该任务解耦为先定位再分割的方案(LTS, Locate then Segment),它在直观上也与人类的视觉感知机制相同。比如给定一句语言描述,人们通常首先会注意相应的目标图像区域,然后根据对象的环境信息生成关于对象的精细分割结果。该方法虽然很简单但效果较好。在三个流行的基准数据集上,该方法大幅度优于所有以前的方法。这个框架很有希望作为指代性分割的通用框架。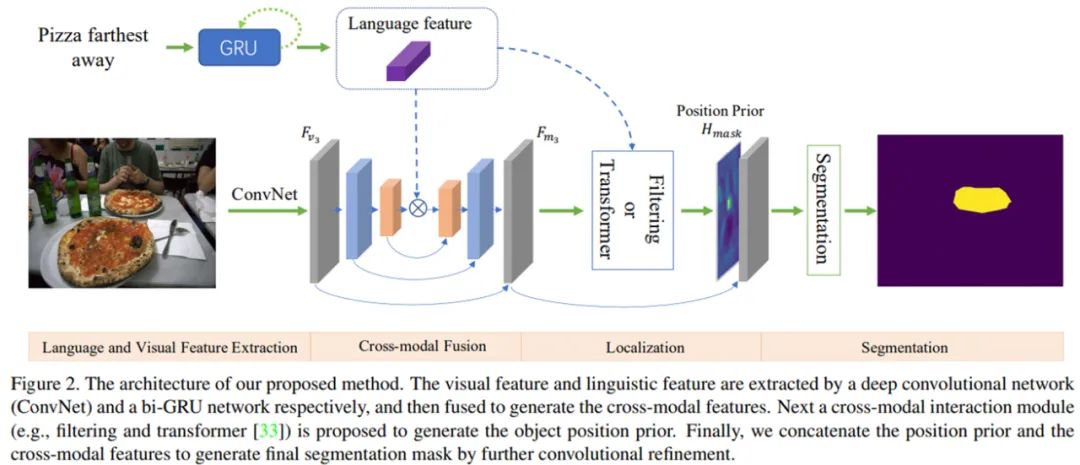
ArXiv Weekly Radiostation机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. Capturing Logical Structure of Visually Structured Documents with Multimodal Transition Parser.? (from Christopher D. Manning)2. ZEN 2.0: Continue Training and Adaption for N-gram Enhanced Text Encoders.? (from Tong Zhang)3. Improving Response Quality with Backward Reasoning in Open-domain Dialogue Systems.? (from Maarten de Rijke)4. Assessing Dialogue Systems with Distribution Distances.? (from Deng Cai)5. Scaling End-to-End Models for Large-Scale Multilingual ASR.? (from Tara N. Sainath)6. The Interspeech Zero Resource Speech Challenge 2021: Spoken language modelling.? (from Emmanuel Dupoux)7. Evaluation Of Word Embeddings From Large-Scale French Web Content.? (from Michalis Vazirgiannis)8. BLM-17m: A Large-Scale Dataset for Black Lives Matter Topic Detection on Twitter.? (from Erik Cambria)9. Modeling Social Readers: Novel Tools for Addressing Reception from Online Book Reviews.? (from Vwani Roychowdhury)10. Adapting Coreference Resolution for Processing Violent Death Narratives.? (from Kai-Wei Chang)1. Aligning Subtitles in Sign Language Videos.? (from Andrew Zisserman)2. Lane Graph Estimation for Scene Understanding in Urban Driving.? (from Wolfram Burgard)3. The Pursuit of Knowledge: Discovering and Localizing Novel Categories using Dual Memory.? (from Rama Chellappa)4. GODIVA: Generating Open-DomaIn Videos from nAtural Descriptions.? (from Guillermo Sapiro)5. DriveGAN: Towards a Controllable High-Quality Neural Simulation.? (from Antonio Torralba)6. VideoLT: Large-scale Long-tailed Video Recognition.? (from Larry Davis)7. RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition.? (from Xiangyu Zhang)8. Unsupervised Discriminative Embedding for Sub-Action Learning in Complex Activities.? (from Mubarak Shah)9. COMISR: Compression-Informed Video Super-Resolution.? (from Ce Liu, Ming-Hsuan Yang, Peyman Milanfar)10. Multi-Perspective LSTM for Joint Visual Representation Learning.? (from Fernando Pereira)
本周 10?篇 ML 精选论文是:
1. Iterated learning for emergent systematicity in VQA.? (from Aaron Courville)2. Graph Learning: A Survey.? (from Huan Liu)3. The Tracking Machine Learning challenge : Throughput phase.? (from Isabelle Guyon, Andrey Ustyuzhanin)4. Deep Convolution for Irregularly Sampled Temporal Point Clouds.? (from Thomas G. Dietterich)5. EBIC.JL -- an Efficient Implementation of Evolutionary Biclustering Algorithm in Julia.? (from Jason H. Moore)6. Preference learning along multiple criteria: A game-theoretic perspective.? (from Peter L. Bartlett, Martin J. Wainwright)7. Learning 3D Granular Flow Simulations.? (from Sepp Hochreiter, Johannes Brandstetter)8. Effective Sparsification of Neural Networks with Global Sparsity Constraint.? (from Tong Zhang)9. Federated Learning with Fair Averaging.? (from Zheng Wang)10. CrossWalk: Fairness-enhanced Node Representation Learning.? (from Krishna P. Gummadi)??THE END?
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/







 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




