在 WAIC 2021 AI 开发者论坛上,九章云极 DataCanvas 董事长方磊发表主题演讲《Hypernets:自动化机器学习的基础框架》,在演讲中,他主要介绍了 Hypernets 的概念模型和两个具体实例。他认为,好的 AutoML 框架一定要具备富有表现力的搜索空间描述语言、支持高维空间的高效搜索算法和高性能的评估策略。
以下为方磊在 WAIC 2021 AI 开发者论坛上的演讲内容,机器之心进行了不改变原意的编辑、整理:
很高兴今天有这个机会跟大家分享我们所做的工作,九章云极 DataCanvas 是一家数据科学平台提供商,服务了众多客户,在服务客户的过程中不断做了沉淀。我们自主研发了 Hypernets,并且已在 GitHub 上开源。各位开发者朋友,如果感兴趣的话可以去 GitHub 搜索 Hypernets 或者搜索 HyperKeras,都能找到所开源的框架。AutoML 是具有共性的问题,我将分三个部分介绍 AutoML:研发 AutoML 框架的原因和基本思路;Hypernets 概念模型和重要性;Hypernets 的具体事例。我将按照程序员标准,仔细讲一讲怎么使用,怎么在开发过程中受益。首先 AutoML 框架本质是什么?就是空间的搜索,空间可以很复杂也可以很简单,大家对于自动机器学习第一个感觉就是调参,事实上,一个算法特别是机器学习和深度学习算法,本质就是空间的搜索。AutoML 也是空间的算法,在算法定义的超维空间里,去搜索到让算法或者一系列算法组合达到最优效果,其中重要的思想是抽象性和层级的必要性。
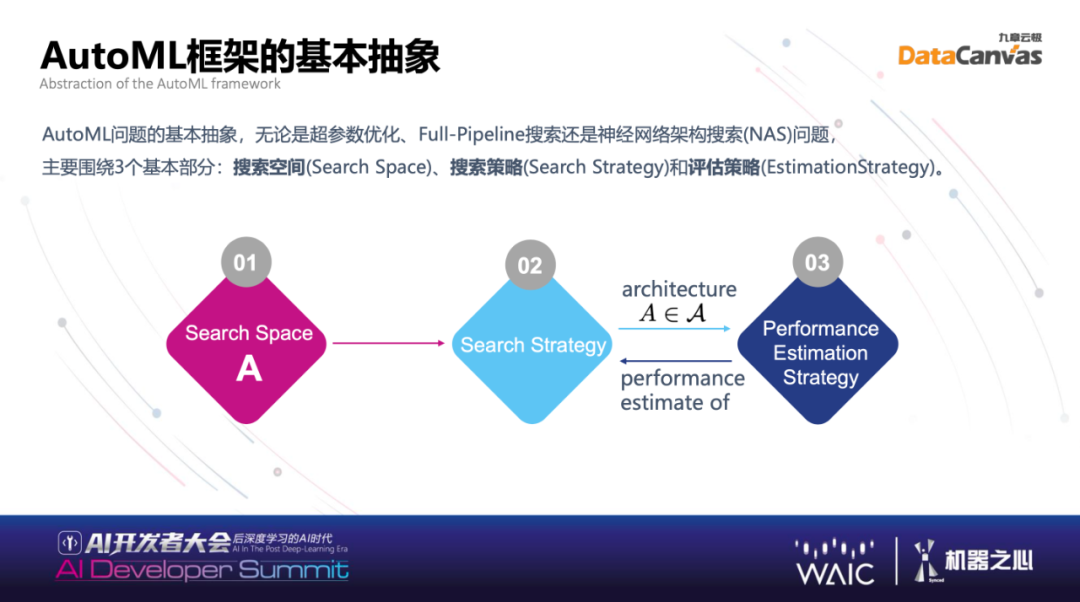
有些算法框架自带自动机器学习的功能,为什么还要做专门框架?目前解决实际问题由很多不同算法框架组合起来,不再只是简单训练一个模型调参数,而多模态也能够实现,视频结构化的模型,训练好的模型变成结构化的数据,再结合结构化的数据,比如看病,除了看非结构化的片子,还有验血等结构化数据。当构建复杂的真实系统的时候,学习的系统、做模型的系统其实是异构的,搜索空间也不是单个算法框架就能带来的。本质上为什么出现这个层级的重要原因就是,定义 AutoML 本身框架,能够让各种算法非常快的实现自动机器学习的搜索。基本的抽象主要围绕三个基本部分:第一步是定义搜索空间(Search Space),第二步是搜索策略(Search Strategy),第三步是评估策略 (EstimationStrategy)。通过搜索结果得到更好的模型,即通过一组参数或者算法组合得到模型后进行评估,评估拥有成本问题。AutoML 框架能够快速低成本评估,并且反馈到搜索策略,搜索策略得到反馈后,找到很好的结果。
?
下面具体介绍 Hypernets 是怎么实现丰富的搜索空间描述语言、灵活的搜索策略、高性能的评估策略?自动机器学习在已有学习框架中,无论运用什么算法框架,在这之上让它变成更好的模型,都可以使用 Hypernets,所以 Hypernets 与现有的各种框架是结合的关系。对于最新的深度学习 NAS 搜索有很多 paper,这是自动机器学习最重要的领域之一,Hypernets 也在其中做了很好的支持。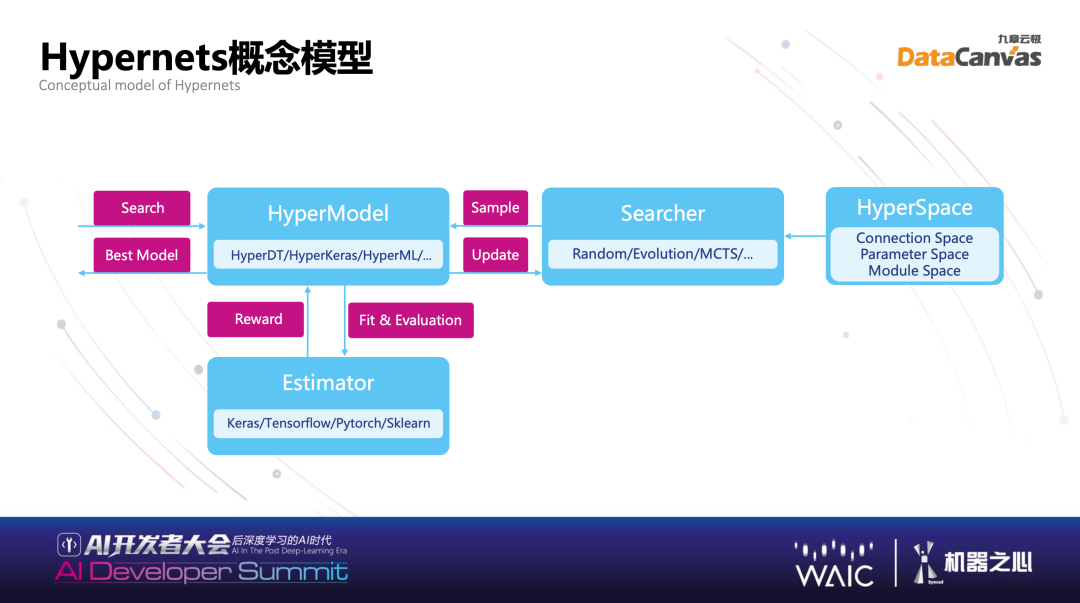
搜索空间本身怎么定义?这是非常经典的定义方式,绝大部分问题可以被定义为一个 DAG,本质搜索空间由三部分组成:一部分叫做 Connection Hypernets,一个点和下一个点连接,拥有有不同的连接方式;另外一个叫 Parameter Space,用算法里的参数,即参数空间;还有 Module Space,算法的使用方式不同,这一步用了算法,下一步可能是填充,不同计算模块本身有模块空间。很多不同的算子代表模块空间,连接方式代表连接空间,参数代表参数空间,将几个不同的空间结合起来就是整个搜索空间。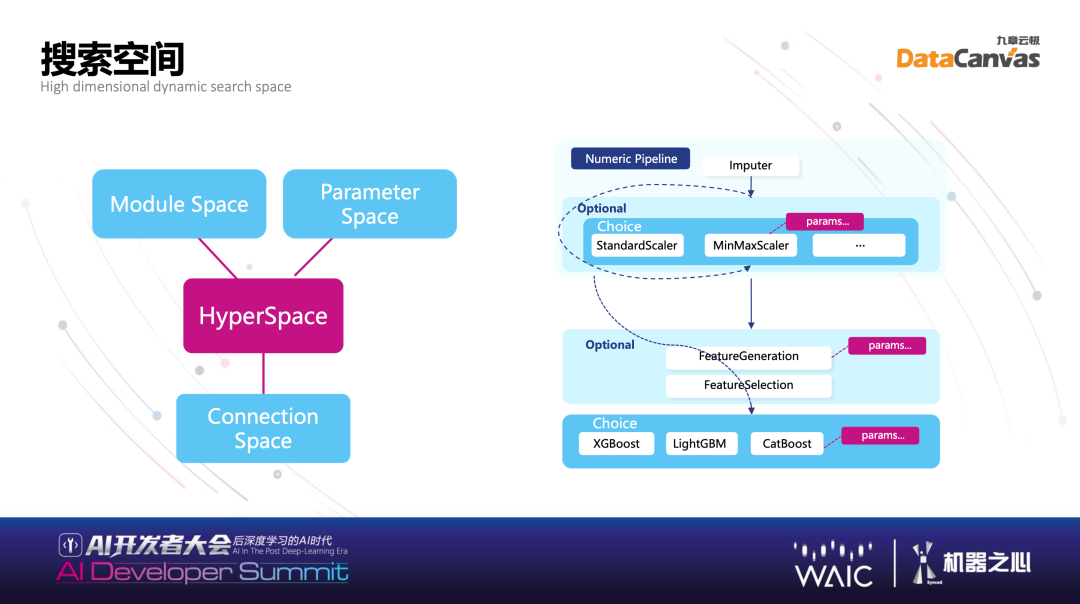
在搜索空间使用什么搜索算法?目前有非常多种类搜索算法可以使用。第一个是大家熟悉的并且阿尔法狗使用的算法——Monte-Carlo Tree Search,在很多科普媒体文章都介绍过,简单来说作为经典算法的 Monte-Carlo Tree Search 是在搜索空间中,进行搜索切割,实现向下或向子空间搜索的算法实践。第二种算法叫遗传算法 (Evolutionary Algorithm),与第一种算法相比,不那么结构有序。但在搜索空间比较复杂的时候,想要找到接近于全局最优的局部最优解,Evolutionary Algorithm 是非常有效的方式。第三类算法 Reinforcement Learning,本身是比较好的一种算法。强化学习的目标是获得最多的累计奖励。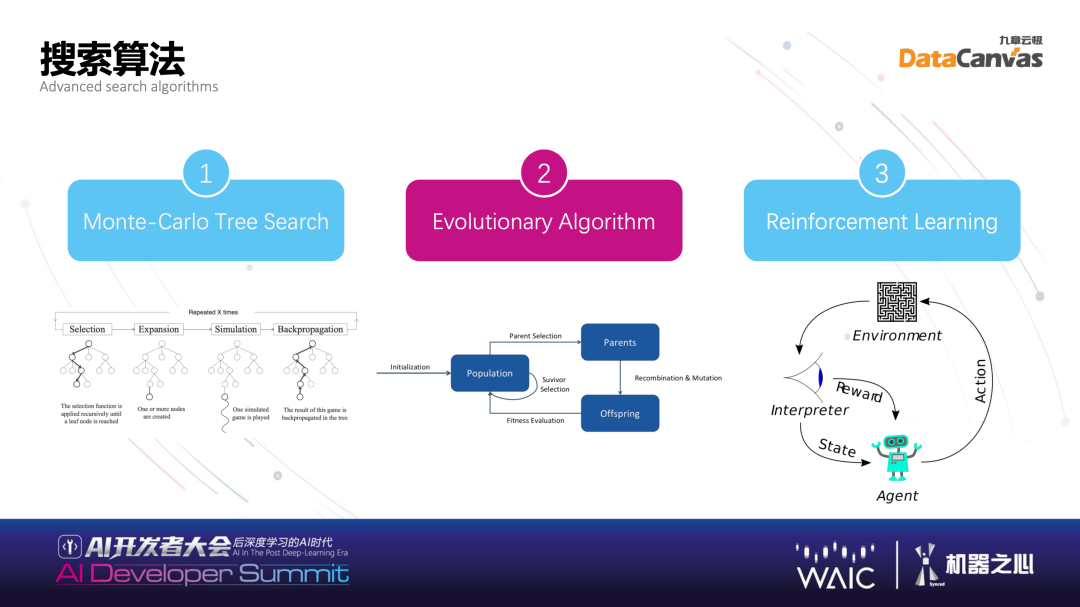
目前算法种类有很多,可以做组合,不同算法组合也可使用增强策略。评估策略在多快好省里最主要的是省,评估的时候在不是太不精确的情况下尽可能减少计算量。评估策略里面主要三个方向:第一,Meta-leaner,指导搜索方向。在搜索过程中使用在线训练的元学习器评估候选参数配置,减少实际执行 Trial 的次数。第二,Caching,节省预处理时间。可以记录很多中间结果,记下来之后可以反复使用,这是缓存的策略。第三,防止过拟合的 Early Stopping。有的时候搜索太深没有用,找到一个貌似很好的点,其实过拟合了,所以会做一些策略防止过拟合,有的时候浅尝辄止也是一件很好的事。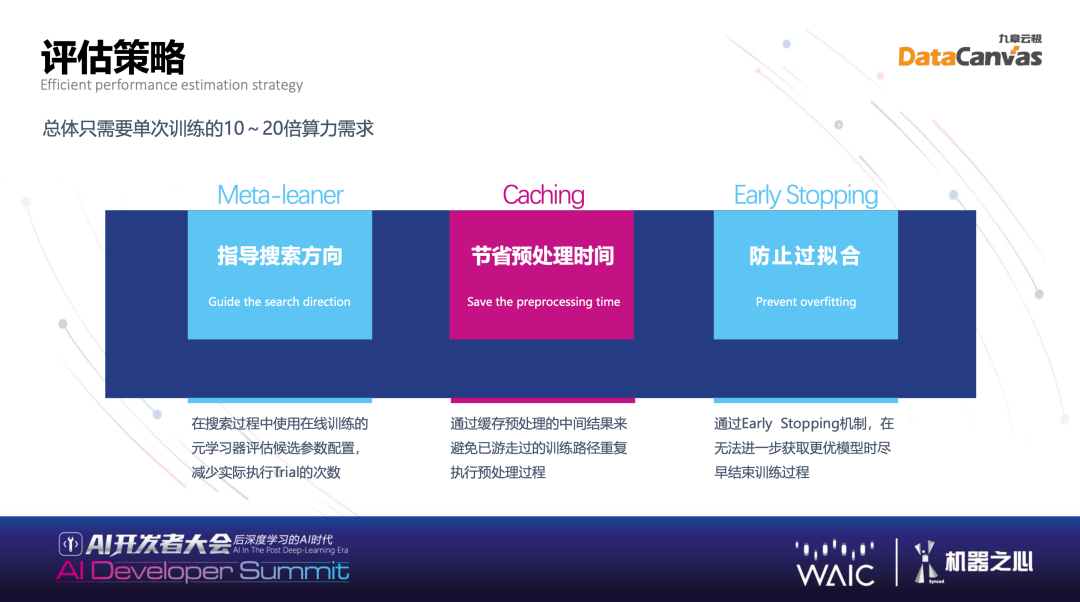
对于高级特性,大家都知道一个框架体现共性的事情是可以解决的,我期待开发者朋友多多使用 Hypernets,Hypernets 也实现了高级的特性。我们经常遇到一些挑战,比如样本不均衡处理以及包括语言学习和二次搜索等特性。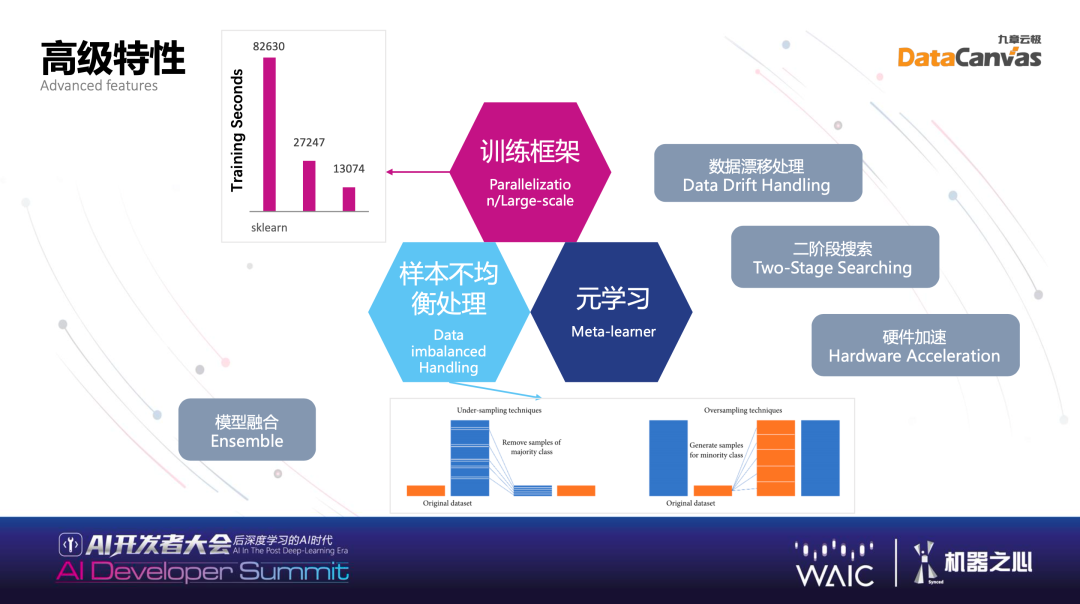
高级特性主要干什么用的?第一,数据漂移,大家碰到非常常见的情况,做了不错的模型,上线后不能运行,因为数据基础分布发生变化,做模型要去检测在历史上哪些数据的分布容易发生漂移,并且作为特别处理。比如在营销中构建推介模型,有很多营销事件,你推荐别人买手机,但是昨天苹果开了发布会,可能大家兴趣变化了,或者华为又开了新的发布会,有非常多事件驱动营销场景下,数据漂移非常严重,这个时候如果有数据漂移的处理会让模型准确度大幅度上升。包括二阶段的搜索,通过不同算法组合,首先运用半监督学习训练,打上标签,其次通过标签引导后面的训练,达到叠加的效果,并且对于样本不均衡的情况也是有很好的效果。包括作为基本功的硬件加速和分布式处理,不可能只在一个机器上训练,在几十上百台机器上都有过应用的案例,所以其拥有较强的性能和分布式的能力。同时也有一些训练适合在 GPU 上训练,不一定是深度学习,也有搜索的内容,均可以拆解。在 GPU 上运行,我们也做了一定探索,能实现一定的硬件加速,实事求是讲,不是特别成熟技术一定大幅度提高,但在一些场景之下有比较大的提升。Hypernets 的具体示例:HyperGBM 与 HyperKeras具体看几个例子,最基础的是 Hypernets,Hypernets 刚刚提到了三个空间,训练服务,在这个基础之上,结合不同的 training 框架,产生不同的 hyper 打头的一系列东西,比如 HyperGBM,是 GBM 加上 Hypernets。我们的定位是去帮助别的框架更好更快的找到训练模型。
https://github.com/DataCanvasIO/Hypernets
https://github.com/DataCanvasIO/HyperGBM
https://github.com/DataCanvasIO/HyperKeras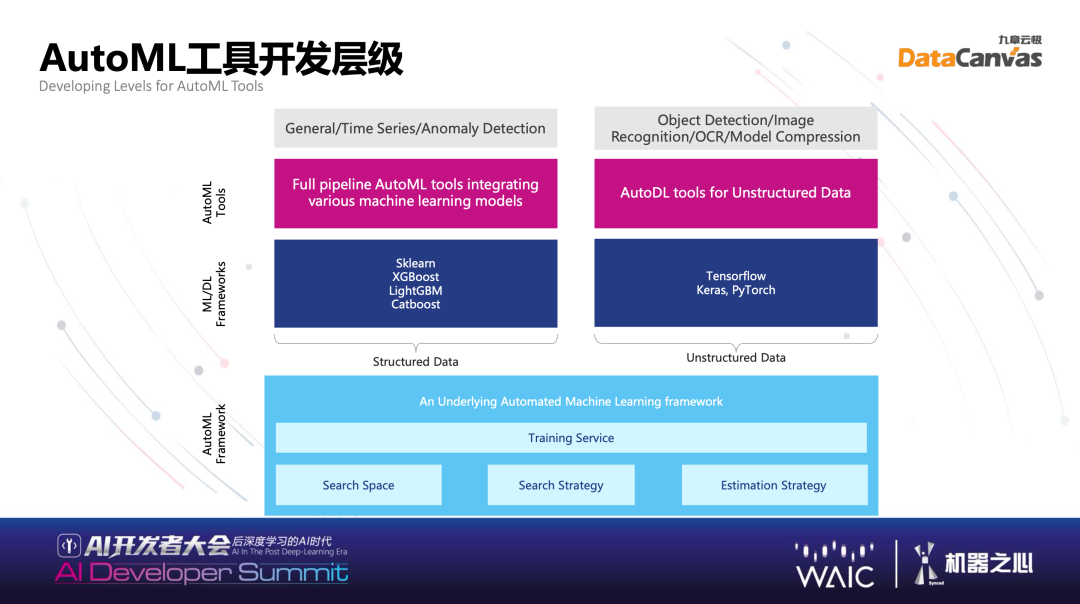
举一个例子,大家最经常使用的 XGBoost、LightGBM、CatBoost 的 GBM 的算法,在结构化数据上有不错的效果。一个 GBM 的算法,一个 Full-Pipeline 可能很长,中间有很多步数据的清洗、切割、特征筛选、特征的组合等等,在中间有很长的 Pipeline,有十几、二十步之多,这个时候你想去利用这个技术怎么自动端到端的优化?运用我们研发的 HyperGBM,简单易用,实现自动端到端优化,当然也可以用强大的 Hypernets 来实现,如果用实现过的 HyperGBM,已经发现能够带来非常简便端到端整个自动机器学习的过程。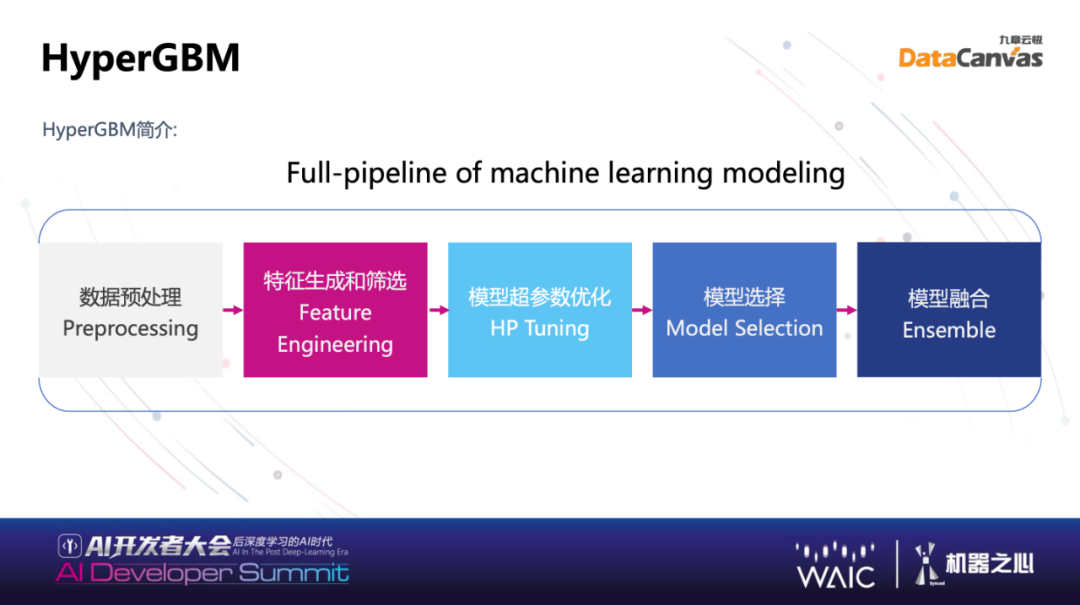
由数据的预处理到特征的筛选、模型参数的优化以及模型的组合,这些结合起来是非常典型的使用 GBM 算法训练的 Pipeline,Pipeline 之上 HyperGBM 实际是调动了 Hypernets 里面不同的 Search 或者自动的组合,在定义好的 SearchSpace 里面,与 GBM 用的算法每一步都有关系,会自动选取不同组合进行自动结合,利用 Search 找到最好的参数。使用 HyperGBM 的五行代码,大大简化开发者使用相对复杂的技术来获得较好的模型。使用五行代码非常简单,在已有的基础上,利用 GBM 算法去进行训练代码技术上增加几行代码,就拥有全自动的搜索能力,大大便捷了我们和客户工作,在更广泛的开源社区里,我们希望开发者也可以使用。
HyperKeras 主要在深度学习上去做一些模型的训练。Deep-learning 总结而言是找网络、找链接,网络里面也要找参数,也就刚才说的空间里面的连接、算子、参数,如果一个简单搜索的网络,可以用 Python 在 Hypernets 定义出来。例如我写了好很多例子,你可以简单使用例子,5-10 行代码完全可以搜索模型。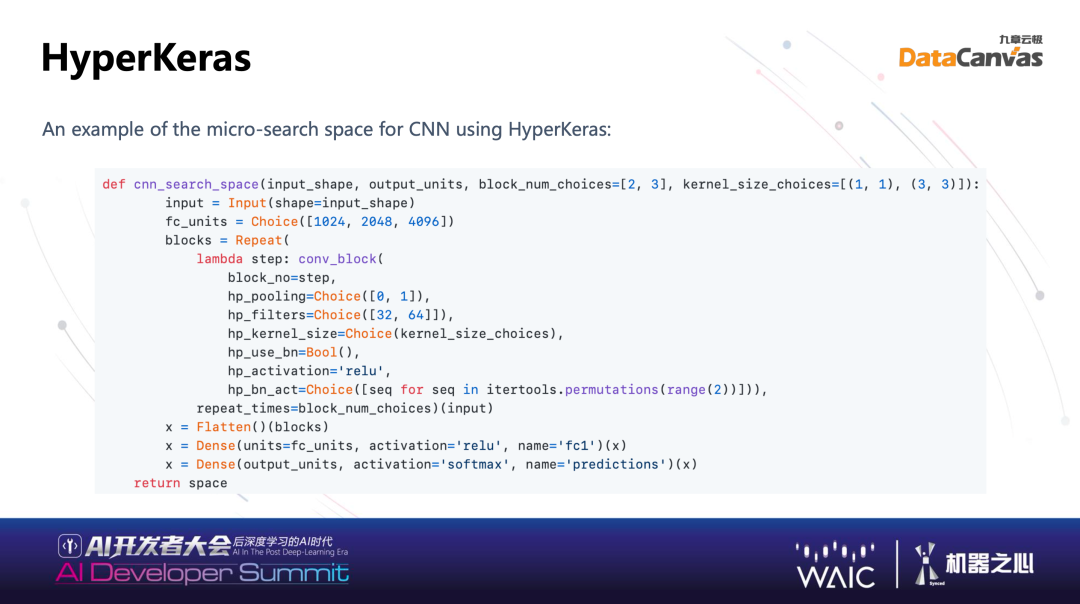
Hyperents 的定位非常清晰,希望成为开发者的朋友,不管开发一个训练框架还是开发应用模型。开发训练框架可以让框架使用 Hypernets 很容易结合出框架本身的自动机器学习能力,如果是开发应用模型,可以组合不同学习训练框架的同时,使用 Hypernets,端到端的 Pipeline 进行自动机器学习的参数搜索,得到非常较好的模型。经过在行业上的大量应用,在特征丰富情况下,Hypernets 在搜索能力包括分布式计算能力体现出来很多优势,搜索时间短,算力仅需普通训练的 20-30 倍,就能够得到一个性能大大提升的模型。
??THE END?
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/







 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




