作者:Shangzhe Wu等
机器之心编译
编辑:陈、杜伟
在 CVPR 2020 最佳论文中,牛津大学 VGG 团队的博士生吴尚哲(Shangzhe Wu)等人提出了一种基于原始单目图像学习 3D 可变形对象类别的方法,且无需外部监督。近日,该团队又提出了通过单目视频的时间对应关系来学习可变形 3D 对象,并且可用于野外环境。
从 2D 图像中学习 3D 可变形对象是一个极其困难的问题,传统方法依赖于显式监督,如关键点和模板。但是,当这些对象不在实验室等可控环境中时,传统方法会限制它们的适用性。有没有可以改进之处呢?近日,牛津大学 VGG 团队的研究者提出了一种全新方法 DOVE(Deformable Objects from Videos),该方法可以在没有显式关键点或模板形状的情况下高效地学习可变形 3D 对象。具体来讲,DOVE 方法基于自然地提供跨时间对应关系的单目视频(monocular video),并且可以应用于「野外」环境。
- 论文地址:https://arxiv.org/pdf/2107.10844.pdf
- 论文主页:https://dove3d.github.io/
DOVE 方法仅使用鸟类的 2D 图像即可预测 3D 标准形状、变形、视点和纹理,因而能够更容易地绘制鸟类动作的动画或操控它们的透视图。研究者提供了一些交互演示动画:


长期以来对象的动态 3D 重建一直是科学家与工程师的目标。现在,DOVE 方法通过其他视频中相机不同角度拍摄的不同视图之间的对应关系,即可从一个视频片段中自动重建一个对象的形状。想象一下,如果几分钟的镜头显示两只鸟停在树上,相机的所有镜头都是静止的。这时这些信息作为输入数据输入到模型中,该模型将具有足够的预测性,能够逐帧模拟下一步会发生些什么,而无需任何额外的训练或指令。不同于现有方法的是,DOVE 方法不需要关键点、视点或模板形状等显式监督,仅依赖视频中固有的时态信息即可学习更多关于对象的几何形状。DOVE 方法也能够高效地创建和绘制对象 3D 表示的动画。DOVE 算法甚至可以在没有关键点或模板形状的情况下从 YouTube 视频中学习。在给定目标检测和光流预处理模型的正确数据时,该系统可以比以前更快地进行训练。该研究的目标是从视频剪辑集合中学习可变形对象类别的 3D 形状。具体来说,给定一个用固定相机捕获的对象短视频剪辑数据集,以此来训练一个重建模型,该模型将对象的单个图像作为输入,并预测其 3D 形状、纹理和 articulated 3D 姿态。下图 2 为训练 pipeline。
重建模型输入来自视频序列的单帧 I ∈ R ^3×H×W,使用三个网络(分别为 f_S、f_T 和 f_P)预测对象的 articulated 3D 形状、纹理和刚性姿态。然后重新组合这些信息以生成(渲染)对象的图像,可以将其与输入视频帧进行比较以进行监督。形状由具有固定连接性和可变顶点位置 V ∈ R^3×K 的三角网格给出。该研究分两步获取 V ,来区分特定于实例的形状变化和特定于帧的关节。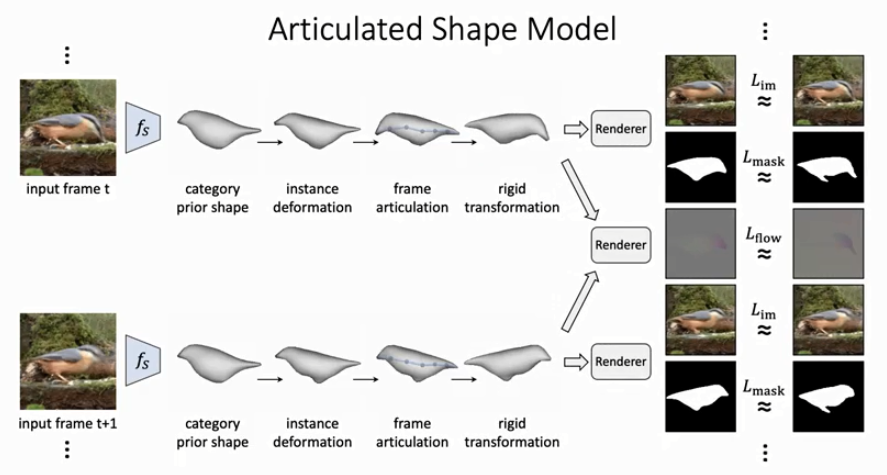
第一步是在规范的「静止姿态」中重建一个特定视频对象实例的形状 V_ins。这解释了不同的对象实例(例如不同的鸟)具有相似但不同形状的事实。形状由下式给出: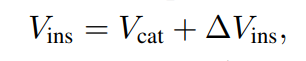
其中,V_cat 是可学习的特定类模板, ?V_ins 为特定于实例的形状变化。该研究的目标是从视频序列集合 中学习重建模型,其中每个序列 S_i 包含帧
中学习重建模型,其中每个序列 S_i 包含帧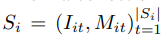 ,其中,i 为序列索引,t 为帧索引(时间)。这些序列是通过使用实例分割技术 Mask R-CNN 对视频进行预处理获得的。
,其中,i 为序列索引,t 为帧索引(时间)。这些序列是通过使用实例分割技术 Mask R-CNN 对视频进行预处理获得的。
数据集包括大量的鸟类短视频片段,这些视频片段来自 YouTube。Mask R-CNN 用来检测和分割鸟类实例,之后视频被自动分割成片段,每个片段包含一只鸟,图片大小调整为 128 × 128 用于训练。下图 3 为单帧重建结果,注意在推理过程中不在需要视频。该研究不需要显示 3D、视点或者关键点信息进行监督,仅从单目训练视频中重建准确的 3D 形状。
该研究还与 SOTA 模型进行了比较,模型包括 CMR、U-CMR、UMR、VMR,结果如表 2 所示,由结果可得,该研究提出的模型实现了更好的形状重建和时间一致性。
下图 4 展示了不同方法之间的定性比较。在以往的方法中,CMR 方法生成了最具鲁棒的重建结果,这得益于它依赖关键点监督,但对于一些挑战性的姿态依然表现不佳,如主视图等。DOVE 在没有使用关键点或模板监督的情况下重建了准确的形状和姿态。并且与其他方法相比,该方法获得的重建结果具有更高的时序一致性。需要注意,研究者的模型是在 128 × 128 图像上训练的,其他方法在 256 × 256 图像上训练(除了 U-CMR),并且从输入图像中采样纹理,因此纹理质量存在差异。
为了给国内 NLP 社区的从业人员搭建一个自由轻松的学术交流平台,机器之心计划于 7 月 31 日组织「ACL 2021 论文分享会」。ACL 论文分享会设置 Keynote、 论文分享 、圆桌论坛、 Poster与企业展台环节 。Keynote 嘉宾包括字节跳动人工智能实验室总监李航和华为诺亚方舟实验室语音语义首席科学家刘群,创新工场首席科学家周明将作为圆桌论坛嘉宾参与此次活动。欢迎论文作者、AI 社区从业者们点击「阅读原文」报名参与。

??THE END?
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/







 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




