Transformer 开始进军决策领域了,它能否替代离线强化学习呢?近日,UC 伯克利、FAIR 和谷歌大脑的研究者提出了一种通过序列建模进行强化学习的 Transformer 架构,并在 Atari、OpenAI Gym 等强化学习实验平台上媲美甚至超越 SOTA 离线 RL 基线方法。
自 2016 年 AlphaGo 击败李世石开始,强化学习(Reinforcement Learning)在优化决策领域可谓是风头无两。同年,基于强化学习算法的 AlphaGo 升级版 AlphaGo Zero 更是采用「从零开始」、「无师自通」的学习模式,以 100:0 的比分轻而易举打败了之前的 AlphaGo。与此同时,BERT、GPT 等语言模型在 NLP 领域掀起狂潮。去年 DETR 和 ViT 出来之后,Transformer 在计算机视觉领域也是大杀四方。而多亏了深度学习,我们今天能做的比几年前要多出许多。处理序列数据的能力,如音乐歌词、句子翻译、理解评论或构建聊天机器人,所有这些都要归功于序列建模(Sequential Modeling)。那么能否结合强化学习与序列建模,并构建优化决策的 Transformer 架构呢?近日,UC 伯克利、FAIR 和谷歌大脑的研究者发布了一篇论文,就此问题展开了研究并提出了 Decision Transformer——一种通过序列建模进行强化学习的架构。首先,为了使用 Transformer 架构的简单性和可扩展性,以及 GPT-x 和 BERT 等语言建模的优势,研究者引入了一个框架,将强化学习抽象为序列建模问题。然后将强化学习问题转化为条件序列建模的架构,提出了 Decision Transformer。与先前拟合值函数或计算策略梯度的方法不同,Decision Transformer 通过利用因果掩蔽的 Transformer 来输出最佳行动。根据期望奖励、过去的状态和行动来调节自回归模型,Decision Transformer 模型能够生成实现期望回报的未来行动。尽管很简单,Decision Transformer 在 Atari、OpenAI Gym 和 Key-to-Door 任务上达到甚至超过了最先进的无模型离线强化学习基线性能。
论文链接:https://arxiv.org/pdf/2106.01345.pdfGitHub 链接:https://github.com/kzl/decision-transformer当前,该研究已经引起业内极大的关注,官方代码库已经有 750 + 的 star 量。研究者首先研究了如何通过在语言建模框架中提出顺序决策问题来改变对强化学习的观点。虽然强化学习中的传统工作使用了依赖 Bellman 备份的特定框架,但用序列建模来作为替代对轨迹进行建模使其能够使用强大且经过充分研究的架构(如 Transformer)来生成行为。为了说明这一点,研究者研究了离线强化学习,从固定的数据集上训练模型,只需最少的更改就能够使用与语言建模框架相同的代码来训练强化学习策略。最近的各项成果表明,Transformer 可以大规模地对语义概念的高维分布进行建模,包括语言中的有效零样本泛化和分布外图像生成。鉴于此类模型成功应用的多样性,研究者想要验证它们能否用于形式化为强化学习的序列决策问题。与以往使用 Transformer 作为传统强化学习算法中组件的架构选择相比,他们试图研究生成轨迹建模,即对状态、动作和奖励的序列联合分布进行建模,以替代传统强化学习算法。此外,研究者还考虑了以下范式转变:使用序列建模目标,根据采集的经验来训练 Transformer 模型,而不是通过传统的强化学习算法(如时序差分学习)来训练策略。这将使研究者绕过对长期信用分配进行自举的需要,从而避免已知会破坏强化学习稳定的「deadly triad」之一。它还避免了时序差分学习(temporal difference,TD)中可能会导致不受欢迎的短视行为,减少未来奖励的需求。此外,利用在语言和视觉领域广泛应用且易于扩展的 Transformer 框架,可以进行大量稳定的训练。除了长序列建模能力之外,Transformer 还具有其他优势,比如可以通过自注意力(self-attention)直接执行信用分配。这与缓慢传播奖励并容易产生干扰信号的 Bellman 备份相反,可以使 Transformer 在奖励稀少或分散注意力的情况下仍然有效地工作。Transformer 还可以对广泛的行为分布进行建模,从而实现更好的泛化和转移。离线强化学习是从次优数据中学习策略来分配代理,即从固定、有限的经验中产生最大有效的行为。由于错误传播和价值高估,探索非常具有挑战性。但是,在使用序列建模目标进行训练时,这是一项自然的任务。通过在状态、动作和返回序列上训练自回归模型,研究者将策略抽样减少到自回归生成建模,选择作为生成的提示的返回 token 来指定策略的专业知识。Decision Transformer:强化学习的自回归序列建模研究者采用了一种简单的方法:每个模态(返回、状态或动作)都被传递到一个嵌入网络(图像的卷积编码器和连续状态的线性层),然后嵌入通过自回归 Transformer 模型处理,在给定先前 token 的情况下,使用线性输出层进行训练以预测下一个动作。评估也很容易:通过期望的目标返回值(例如成功或失败的 1 或 0)和环境中的起始状态进行初始化,展开序列(类似于语言模型中的标准自回归生成)以产生一系列要在环境中执行的动作。
研究者考虑了固定图上找到最短路径的任务的强化学习问题(累积奖励 = 边权重之和)。在由随机游走组成的训练数据集中,他们观察到了许多次优轨迹。如果在这些序列上训练 Decision Transformer,可以要求模型通过调节高回报来生成最佳路径。如果仅对随机游走进行训练,Decision Transformer 可以学习将来自不同训练轨迹的子序列拼接在一起,以便在测试时产生最佳轨迹。事实上,这与离线强化学习框架中常用的离策略 Q-learning 算法所期望的行为相同。然而,无需引入 TD 学习算法、价值悲观主义或行为正则化,就可以使用序列建模框架实现相同的行为。如下图所示,图左为强化学习为固定图寻找最短路径,图中显示由随机游走轨迹和每个节点的返回组成的训练数据集,图右显示了以起始状态和每个节点产生的最大可能回报为条件,Decision Transformer 对最佳路径进行了排序。
研究者扩展到了离线强化学习文献中常用的基准,即 Atari 学习环境、OpenAI Gym、Minigrid Key-To-Door 任务。在离散和连续控制以及状态和图像观察的多样化任务中,他们发现 Decision Transformer 的性能可以媲美经过充分研究的专业 TD 学习算法的性能。主要比较点是基于 TD 学习的无模型离线强化学习算法,因为 Decision Transformer 架构本质上也是无模型的。此外,TD 学习是强化学习中提高样本效率的主要范式,并且作为一个子程序在许多基于模型的强化学习算法中也很突出。研究者还与行为克隆和变体进行了比较,因为这些也涉及了基于似然的策略学习公式。确切的算法取决于环境,但研究者的动机如下:TD 学习:这些方法中的大多数使用动作空间约束或价值悲观主义,并且将是与 Decision Transformer 最忠实的比较,代表标准的强化学习方法。最先进的无模型方法是 Conservative Q-Learning (CQL),它作为主要的比较方法。此外,研究者还与其他的无模型强化学习算法(如 BEAR 和 BRAC )进行了比较;
模仿学习:这种机制类似地使用监督损失进行训练(而不是 Bellman 备份),并在这里使用行为克隆。
关于评估离散(Atari)和连续(OpenAI Gym)控制任务,前者涉及高维观察空间,需要长期的信用分配,而后者需要细粒度的连续控制,代表不同的任务集。如下图所示,主要结果总结了每个域的平均归一化性能。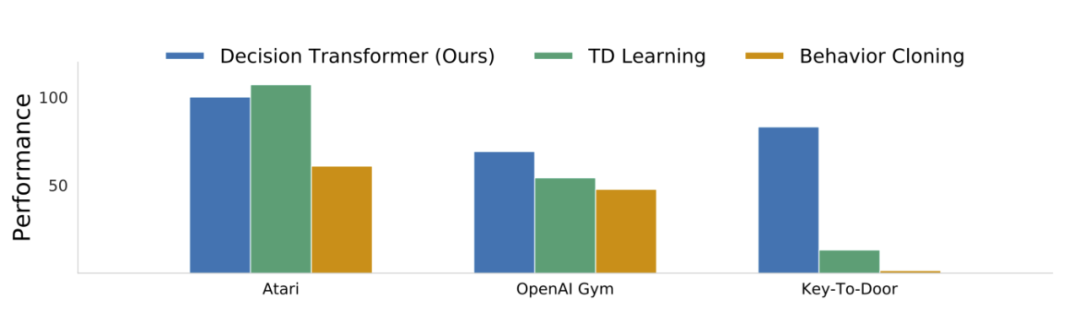
此类型建模的一个效果是执行条件生成:通过输入想要的回报来初始化一个轨迹。Decision Transformer 不产生单个策略,相反它模拟了广泛的政策分布。如果绘制训练后 Decision Transformer 的目标回报与平均获得的回报之间的关系图,就会发现可以合理地匹配目标,并且仅使用监督学习进行训练。此外,在某些任务(例如 Qbert 和 Seaquest)上,研究者发现 Decision Transformer 实际上可以在数据集和模型策略之外进行推理,从而获得更高的回报。研究者通过在很大的范围内改变所需的目标回报来评估 Decision Transformer 理解返回 token 的能力,即评估 Transformer 的多任务分布建模能力。下图显示了当以指定的目标(期望)回报为条件时,Decision Transformer 累积的平均采样(评估)回报,上部为 Atari,底部为 D4RL 中重放数据集。在每项任务中,期望的目标回报和真实观察到的回报是高度相关的。在 Pong、HalfCheetah 和 Walker 等一些任务上,Decision Transformer 生成的轨迹几乎完美匹配所需的回报(如图中与 oracle 线重叠所示)。此外,在诸如 Seaquest 之类的一些 Atari 任务中,Decision Transformer 有时能够进行外推。
NVIDIA对话式AI开发工具NeMo的应用
开源工具包 NeMo?是一个集成自动语音识别(ASR)、自然语言处理(NLP)和语音合成(TTS)的对话式 AI 工具包,便于开发者开箱即用,仅用几行代码便可以方便快速的完成对话式 AI 场景中的相关任务。8月12日开始,英伟达专家将带来三期直播分享,通过理论解读和实战演示,展示如何使用 NeMo 快速完成文本分类任务、快速构建智能问答系统、构建智能对话机器人。
直播链接:https://jmq.h5.xeknow.com/s/how4w(点击阅读原文直达)
报名方式:进入直播间——移动端点击底部「观看直播」、PC端点击「立即学习」——填写报名表单后即可进入直播间观看。
交流答疑群:直播间详情页扫码即可加入。
??THE END?
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/








 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




