稀疏约束通常会引起姿态参数的扰动,其背后的主要原因是缺乏归纳偏置来解决从一小组约束中恢复完整姿势的不适定问题。
人体姿态建模和学习姿态表征在计算机图形与动画、视频中姿态与运动估计、沉浸式 AR、人机交互和自动驾驶等多项应用中具有非常关键的作用,相关研究方法也受到越来越多的关注。在游戏行业,SOTA 实时姿态操纵工具(例如 CCD、FABRIK、FinalIK 等)因其快速执行的特点而受到欢迎,这类工具依赖于通过不可学习的运动方程定义的正向和逆向运动模型。虽然在数学上是准确的,但这些不可学习的运动模型,并不能保证源自稀疏约束(例如关节子集的位置)的欠约束解决方案能够生成合理的人体姿态。相比之下,稀疏约束通常会引起姿态参数的扰动,其主要原因是缺乏归纳偏置来解决从一小组约束中恢复完整姿态的不适定(ill-posed)问题。来自 Unity Technologies 的研究者在一项工作中为高级 AI 辅助动画工具开发了可学习的人体姿态神经表征。具体来说,该研究解决了基于稀疏和可变用户输入(例如身体关节子集的位置和 / 或方向)构建完整静态人体姿态的问题。为了解决这个问题,该研究提出了一种名为 ProtoRes 的新型神经架构,将残差连接(residual connection)与部分特定姿态的原型编码相结合,从学得的潜在空间中创建一个新的完整姿态。该研究表明所提的架构在准确性和计算效率方面都优于 Transformer 基线。此外,该研究还开发了一个用户接口,将该研究所提的神经模型集成到实时 3D 开发平台 Unity 中。该研究基于高质量的人体动作捕捉数据提出了两个表征静态人体姿态建模问题的新数据集 miniMixamo 和 miniUnity,后续数据集将和模型代码一起公开发布。
论文地址:https://arxiv.org/abs/2106.01981

在该研究集成的实时平台上,用户可以从静态剪影图像快速创建人体姿态。方法简单易学,新手用户也能快速掌握。下面的视频展示了该平台的使用效果,通常仅用不到一分钟的时间就能获得完整的人体姿态。该研究提出的 ProtoRes 架构如下图所示,遵循编码器 - 解码器模式,并分三个步骤生成预测。首先,用户提供数量和类型可变的输入,这些输入被处理以实现平移不变性(translation invariance)和嵌入。其次,该架构的核心是 proto-residual 编码器,将通过效应器指定的姿态转换成单个向量(姿态嵌入)。最后,姿态解码器将姿态嵌入扩展到全身姿态表征,包括每个关节的局部旋转和全局位置。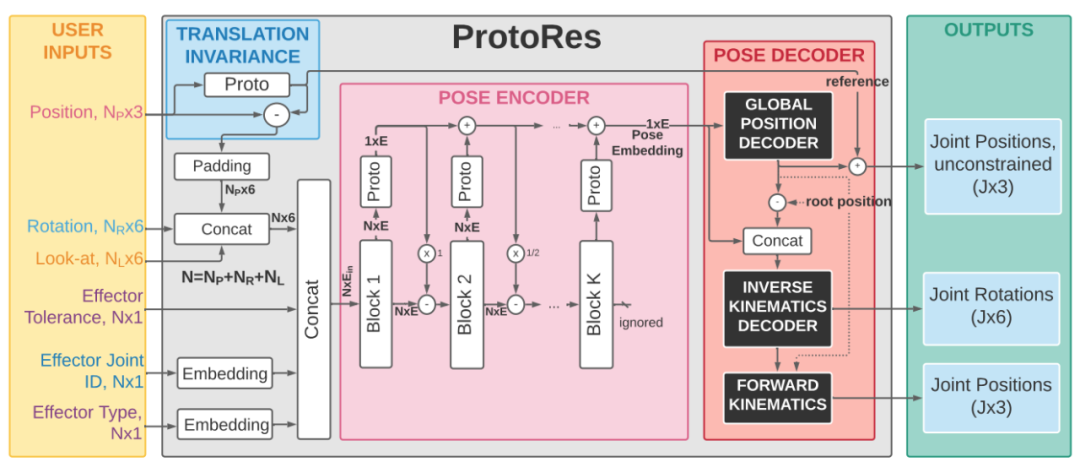
ProtoRes 在用户输入上采用位置(3D 坐标)、旋转(6D 表征)和观察(look-at:3D 目标位置和 3D 局部朝向)效应器。对于位置效应器,6 个维度中有 3 个设置为零。所有位置都相对于位置效应器的质心重新定位,以实现平移不变性。平移不变性简化了全局空间中姿态的处理,同时不依赖于精确的参考系,这对于异构 MOCAP 源的定义可能很棘手。每个效应器的特征还包括容差、关节 ID 和类型。较小的容差意味着在重建姿态中必须更严格地遵从效应器。操纵位置效应器控制和限制某些关节的位置。在每次更新时,ProtoRes 从当前效应器状态生成一个全身姿态:

观察效应器可以根据关节朝向的目标方向来定位,旋转观察效应器还允许控制关节的局部坐标轴与特定目标对齐:
姿态编码器是一个双环路(two-loop)残差网络。第一个残差循环在每个块内实现(如下图(左)所示)。第二个残差循环由前向链路原型组成。残差链接被用来 (i) 改进梯度流;(ii)实现单个关节编码与整体姿态编码之间的交互。
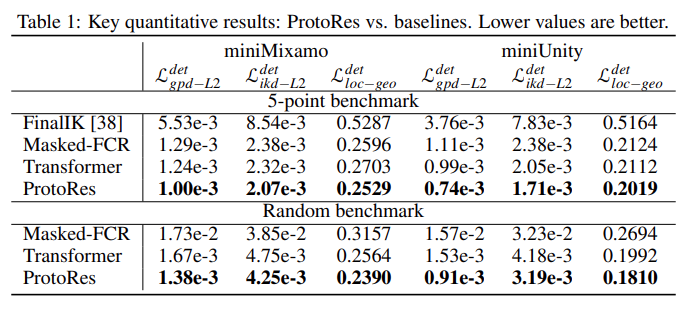
姿态解码器部分包含两个模块:全局位置解码器(GPD)和逆运动学解码器(IKD)。两者都依赖于上图中描述的全连接残差 (FCR) 架构。GPD 将编码器生成的姿态嵌入展开到 3D 关节位置的无约束预测中。IKD 生成骨架(skeleton)的内部几何参数(关节旋转),保证在正向运动学传递之后生成可行的关节位置。正向运动学 (FK) 传递被用于 IKD 的输出,使用骨架运动学方程将局部关节旋转和全局根位置转换为全局关节旋转和位置。ProtoRes 能够比现有的非机器学习 IK 解决方案更准确地重建稀疏定义的姿态;
ProtoRes 比两个基线 ML 模型(一个基于 Transformer,一个基于缺失输入掩码)更准确;
该研究提出的两阶段 GPD+IKD 解码比单阶段解码更有效;
该研究提出的随机损失加权在多任务训练场景中有效;
使用测地线(Geodesic)和 L2 损失的多任务训练会产生协同效应。
为了研究模型中各种因素的影响,该研究进行了一系列消融实验来探究全局位置解码器(GPD)、损失函数、损失权重的作用,实验结果如下表 2 所示。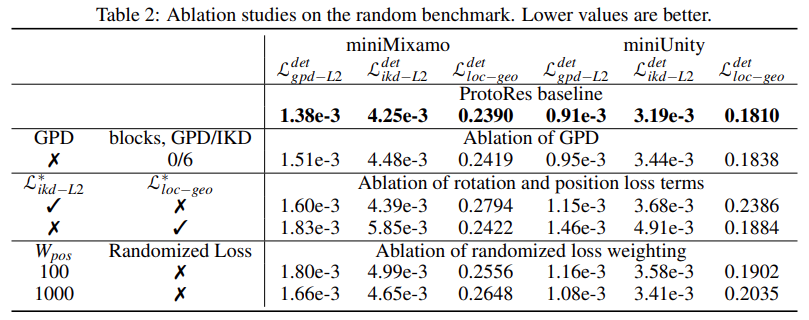
参考链接:https://unity-technologies.github.io/Labs/protores.html基于Python,利用 NVIDIA TAO Toolkit 和 Deepstream 快速搭建车辆信息识别系统
NVIDIA TAO Toolkit是一个AI工具包,它提供了AI/DL框架的现成接口,能够更快地构建模型,而不需要编码。DeepStream是一个用于构建人工智能应用的流媒体分析工具包。它采用流式数据作为输入,并使用人工智能和计算机视觉理解环境,将像素转换为数据。
DeepStream SDK可用于构建视觉应用解决方案,用于智能城市中的交通和行人理解、医院中的健康和安全监控、零售中的自助检验和分析、制造厂中的组件缺陷检测等
12月14日19:30-21:00,本次分享摘要如下:
介绍 TAO Toolkit 的最新特性;
介绍 NVIDIA Deepstream 的最新特性;
利用 TAO Toolkit 丰富的预训练模型库,快速训练模型;
直接利用 TAO Toolkit 的预训练模型和 Deepstream 部署应用;

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/







 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号





