
北京时间2月24日,本篇工作作者申万祥博士将带来线上分享,介绍如何通过增强数据的表征和利用卷积神经网络来提高生物医学数据的学习效果。更多详情见文末。
决定 AI 模型识别能力的主要因素是数据和算法,长久以来 AI 领域重点关注在算法来提升性能,但对数据的探索程度远不及算法的开发。以数据为中心的 AI 方法(data-centric AI)基于高质量的数据构建 AI 系统,主要是确保数据表征能够清晰地展示 AI 所须学习的内涵特征。
特别是对于生物医药领域具有高维度而无序特征的小样本数据(比如疾病组学数据),合适的数据表征对AI模型的提升效果可能远远大于模型算法本身的提升。来自新加坡国立大学、清华大学深圳国际研究生院的研究者,合作开发了一个无监督创新方法 AggMap,将无序数据结构化并以 3D 图像的表征形式提供后续AI学习, 进而生成结构化的特征图谱,大幅提升模型的学习效率,尤其适用于组学数据的分析。作者表示,该工作提供了一套有用的学习范式,未来可能被用于其他领域的数据的学习中。该方法以「AggMapNet: enhanced and explainable low-sample omicsdeep learning with feature-aggregated multi-channel networks」为题,于2022 年 1 月 31 日发布在国际著名生物信息学期刊《Nucleic AcidsResearch》。卷积神经网络(CNN)本身的输入是 3D 的图像数据,图像数据的像素点是二维空间相关的、拓扑链接的,此外 RGB 多通道的彩色图像丰富了数据的信息。
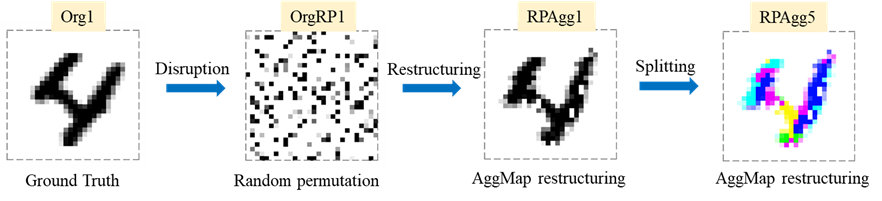
传统的机器学习方法如 SVM, KNN,RF,DNN 与 CNN 相比,模型的输入的时候没考虑像素特征点的之间的关联性,所以性能不如 CNN。假如把图像的像素随机排列而形成「雪花图」,则 CNN 模型的学习效率则大大降低。这说明高性能的 CNN 模型依赖于像素点的空间局部相关性,而基于多通道数据的 CNN 表现也好于单通道的数据。基于以上的背景,作者开发了高维度、小样本数据的结构化算法 AggMap, 将 1 维的无序矢量转化为 3D 的结构化的、类似图像的数据作为卷积神经网络 AggMapNet 的输入。为了验证 AggMap 数据结构化的能力,作者首先将手写字体 MNIST 像素点随机排列(像素点打乱形成雪花图),然后使用 AggMap 基于雪花图进行数据结构化,来探索其结构化能力。令人惊讶的是,无监督的 AggMap 基于特征点的内在相关性,竟然能完全重构这些随机的像素点而形成与原始图像高度一致的图像:图 1:AggMap 重构随机MNIST像素点,Org1: 原始的黑白图像,通道数为1;OrgRP1: 原始的图像被打乱后的 “雪花图” ;RPAgg1: AggMap 基于被打乱后的“雪花图“而无监督重构的图像;RPAgg5: AggMap 进一步基于聚类的多通道分割的彩色图像,通道数为 5 。
无监督 AggMap 究竟是什么方法?
人类能够对破碎图片的碎片进行逻辑恢复,例如解决拼图游戏或文物的修复,如图 2A 所示。这种能力源于预先学习的先验知识,可以根据片段的相关性和边缘连接来连接和组合片段。这些知识是通过大量碎片恢复过程学习得到的。然而,尽管人们能够从较大的碎片中修复物体,但无法重建像素点被随机排列的图像(例如,从图 2B 中的图像「a」到图像「b」)。这是因为图像从「b」到「a」的原始信息已经完全丢失。
尽管如此,人们可以根据「a」中像素(特征点,FP)的相似性将图像从「a」重构为「c」。新图像「c」比图像「a」更有结构,甚至在花朵、树干和树叶等各种图案上的模式非常接近原始图像。所提出的 AggMap 旨在通过以自监督的方式模仿人类的组装能力(解决拼图游戏),将 1 维无序的特征点聚合和映射成 3D 结构化的特征图(Fmap)。这种结构化过程能够将无序的特征点映射到结构化模式中,以增强 CNN 更有效地对无序数据的学习。图 2:重建和结构化过程的示例图。(A)将破碎的碎片恢复为具有特定模式的物体图像。(B)将随机排列的图像分别重建和结构化为原始图像和结构化的图像。所以,作者将 AggMap 称为特征点的「拼图求解器」(Jigsaw puzzle solver),旨在通过特征点(feature point, FP)本身的内在相关性和拓扑连接性来将一系列的高维度、无序的特征点拼图般地聚集在一起,形成一个具有特定模式的、有序的、多层的、结构化的特征图谱(feature map),AggMap 的特征点拼图是通过自监督来完成。?图 3:特征点拼图求解器 AggMap,每个像素块相当于一个特征点。具体来讲,自监督的 AggMap 来结构化特征点主要分为以下几个步骤(如图 4 所示):总结来说,自监督 AggMap 使用了 UMAP 思想,通过学习其数据的内在结构来结构化无序的特征点。其代理任务是最小化在输入数据空间构建的和嵌入二维空间中构建的两个加权拓扑图之间的差异。因此,AggMap 是通过流形学习和层次聚类来暴露特征点的拓扑结构和分层结构,以此来生成结构化的特征图谱。
无监督AggMap重构随机打乱的MNIST图像
为了测试 AggMap 的特征结构化能力,作者将 MNIST 数据任意随机打乱生成「雪花图」,「雪花图」完全丢失了原有图像的数据模式。然后基于像素点无序的「雪花图」来使用 AggMap 进行数据结构化。AggMap 数据结构化的过程中,本质上是基于 UMAP 思想最小化交叉熵损失函数 CE(最小化加权图 D 和 F 的差异)的过程。作者采用了 500?次迭代来进行优化加权图F的布局,动态视频如下所示。(示例代码见:https://github.com/shenwanxiang/bidd-aggmap/blob/master/paper/example/01_mnist_restore/MNIST-AggMap.ipynb)
视频 1:AggMap 重构像素被打乱的 MNIST 的动态过程。
视频 2:AggMap 重构像素被打乱的 MNIST 的动态过程 2。此视频包含 0-9 的数字在重构过程中的动态变化。
随着迭代次数(epochs)的增加,生成的 Fmap 变得更加结构化,并最终在损失达到收敛时形成稳定的模式。
AggMap 可以恢复随机排列的 MNIST 的原因是,作者认为尽管像素点已经随机排列(打乱),但 MNIST 的像素特征点的流形结构并没有完全改变(即拓扑结构仍然可以通过它们的成对相关性来近似),并且流形结构可以用低维的加权图来近似。尽管 AggMap 可以将随机化的 MNIST 大致地还原为原始图像,然而无法将随机化的F-MNIST 还原。MNIST 是曲线形数据,特征像素点之间的相关性不是离散的而是更均匀分布,这符合 UMAP 的数据均匀分布假设。作者在 AggMap 特征重组的图形布局优化阶段比较了 MNIST 与 F-MNIST 的交叉熵 CE 损失和 PCC相关性。MNIST 具有更低的损失和更高的 PCC 值,表明 MNIST 中的 2D 嵌入分布更类似于原始数据的拓扑结构。MNIST FP 的最终 2D 嵌入也比 F-MNIST FP 的分布更均匀。因此,AggMap 可以重构随机 MNIST,部分原因是尽管MNIST 像素点被随机置换,但像素点之间的流形结构并没有完全改变,并且流形结构可以通过低维加权图来近似。随机化的F-MNIST 被重组为更紧凑的模式,其中一些局部补丁恢复为原始补丁。因此,AggMap 可以将随机化的 F-MNIST 重构为高度结构化的形式,即使它不能完全恢复为原始图像。由于特征点的之间的相关性是根据样本来衡量的,因此样本量的大小不同可能导致特征点之间的相关性距离有差异。非常小的样本可能无法准确衡量特征点的内在相关性。AggMap 具有单独的拟合(fit)和转换(transform)阶段,这有助于在大量无标签的样本上进行特征点的距离测量(或者预训练)。作者分别使用了像素随机排列的MNIST训练集的 1/1000(60样本)、1/100(600样本)、1/10(6千个样本)、1/5(1.2万个样本),1/2(3万个样本)和全部 6 万个样本进行预训练(如图 5),得到的结构化程度也不一致。非监督拟合的样本量越大,其生成的特征图谱越结构化,随机打乱的 MNIST 也越接近真实的数字。图 5:AggMap 预拟合在不同数量的随机排列图像以重建 MINST 图像(RPAgg1)。
基于聚类的多通道的优势
AggMap 数据结构化主要聚焦在特征在 2D 的空间相关和多通道上。为了进一步增强基于 CNN 的模型 AggMapNet 对无序数据的学习效率,作者使用了基于聚类的多通道生成策略。该思想创新性地将特征点聚类成 C 个聚类簇(cluster),每个聚类簇的特征点将被分配到一个单独的通道中。与单通道相比,多通道特征图谱是一种非堆叠形式的数据表征。C 越大,特征点被越细粒度地分开,作者通过实验结果证明了该方法对于 CNN 模型 AggMapNet 的提升效果非常显著。多通道的数据表征有明显的优势,如图 6 所示,在一个细胞周期数据集上(5 个样本,每个样本是一个细胞周期,每个周期都有 5162 个基因表达,但表达量不一样),通过聚类的多通道方式(增加通道数),很容易选出各个周期特异性的基因。这相当于特征选择性学习,对于高维度的特征,避免了传统方法的特征选择过程,实现了自动化、多层次的学习。图6:AggMap 在细胞周期数据集CCTD-U重构上的表现。作者进一步在不同数据集上测试了多通道对模型性能的影响,如图 7 所示。多通道与单通道(C=1)相比,能够显著提升模型的性能。通道数越多,效果越好,但过多的通道数可能引起过拟合。因此通道数是一个超参数,但是整体而言,多通道对模型的提升效果非常显著。图 7:通道数对 AggMapNet 模型的性能影响。
AggMapNet的可解释性与应用
为了增强基于 CNN 的 AggMapNet 模型的可解释性,作者还集成了两种模型无关的特征归因方法:基于核 Shapley 值的解释方法(Shapley-explainer)和基于简单的特征替换的方法(Simply-Explainer)。虽然核 Shapley 方法基于博弈论的坚实理论基础,并且是被广泛用于模型未知的特征重要性计算,但作者提到它在特征重要性的测量中存在 2 个主要问题:第一,是在计算全局特征重要性的时候计算复杂度是指数级别的,在高维数据中使用 Shapley-explainer 计算特征重要性非常耗时。第二,是由于核 Shapley方法考虑的是每个特征对模型预测值(而不是真实值)的贡献量,因此它可能无法充分探索特征与真实结果之间的全局关系。作者开发了 Simply-explainer 是为了为 AggMapNet 模型解释提供额外的方法。Simply-explainer 旨在更快地计算高维组学特征的全局特征重要性,并考虑特征与真实标签的关系。图 8:AggMapNet 中的 Simply-Explainer 计算特征重要性的过程。作者比较了 Shapley-explainer 和 Simply-explainer 的解释效果。在 MNIST 识别模型的局部解释中,Simply-explainer 在 MNIST 图像识别模型中上显示出比 Shapley-explainer 更高的 PCC 和 SSIM 值。此外,在乳腺癌诊断模型的全局解释上,两个解释器计算的全局特征重要性(GFI)高度相关。然而,Simply-explainer 的计算复杂度比 Shapley-explainer 低得多。并且Simply-explainer 中的特征重要性得分往往比 Shapley-explainer 更离散,这表明 Simply-explainer 可以成为鉴定关键生物标志物的竞争方法。作者进一步使用 AggMapNet 可解释模块 Simply-explainer,来基于高维的蛋白质组和代谢组数据来确定用于 COVID-19 严重程度预测的关键代谢物和蛋白质。这些关键关键代谢物和蛋白质与文献报道的高度一致。这些解释结果表明,Simply-explainer 可能是揭示重要特征的更好选择。Simply-explainer 还表现出对特征重要性的高度区分,计算结果非常快,特别适合揭示高维数据集中的关键生物标志物。图 9:AggMapNet 中的 Shapley-explainer 和 Simply-explainer 在 MNIST 识别模型中的解释效果对比。
讨论与结论
这篇论文的主要思想是基于无监督方法进行数据结构化,之后使用卷积神经网络学习数据。通过非监督的 AggMap 和监督训练的 AggMapNet,提供了一套高维无序数据学习的流程。在无监督数据结构化中,聚焦在「局部空间相关」和「多通道」上的优化,显著提升模型的性能,说明合适的数据表征对模型的学习起到极大的作用。结构化数据的?AggMap?可以用作迁移学习,也即在大量无标签样本上进行特征点的相关性预计算,然后在小样本有标签的数据上做转换,从而生成结构化的特征图谱,提升模型的学习效率。该方法非常有利于高维小样本的表格数据的学习(Tabular data, 每一行是一个样本,每一列是一个特征)。AggMap/AggMapNet 提供了一套有用的学习范式,未来,它可能会被用在其他领域的数据学习中。线上分享
北京时间2月24日,机器之心最新一期分享邀请到本篇工作作者申万祥博士,为大家介绍如何通过增强数据的表征和利用卷积神经网络来提高生物医学数据的学习效果。
分享嘉宾:申万祥博士,目前就读于新加坡国立大学(NUS)药学院,即将博士毕业并入职NUS化学系,从事AI辅助的药物设计与合成的研究。他曾供职于AI公司如清华数据创新基地D-lab、北京旷视科技研究院等并担任数据科学家、视觉算法研究员等职位。他的主要研究兴趣包括基于机器学习的组学数据发掘和药物发现、药物设计、以及生物医学数据学习算法的开发,在Nature Machine Intelligence、Nucleic Acid Research等国际期刊上发表多篇学科交叉的相关论文。
分享时间:北京时间2月24日19:00-20:00
直播间:关注机动组视频号,北京时间2月24日开播。
交流群:本次直播设有 QA 环节,欢迎加入本次直播交流群探讨交流。

如群已超出人数限制,请添加机器之心小助手:syncedai2、syncedai3、syncedai4 或 syncedai5,备注「组学」即可加入。
机动组是机器之心发起的人工智能技术社区,聚焦于学术研究与技术实践主题内容,为社区用户带来技术线上公开课、学术分享、技术实践、走近顶尖实验室等系列内容。机动组也将不定期举办线下学术交流会与组织人才服务、产业技术对接等活动,欢迎所有 AI 领域技术从业者加入。
点击阅读原文,访问机动组官网,观看往期回顾;
关注机动组服务号,获取每周直播预告。
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
















 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




