性能最高提升 6.9 倍,字节跳动开源大模型训练框架 veGiantModel
字节跳动 AML 团队内部开发了火山引擎大模型训练框架 veGiantModel,比 Megatron 和 DeepSpeed 更快。
同时支持数据并行、算子切分、流水线并行 3 种分布式并行策略,同时支持自动化和定制化的并行策略;
基于 ByteCCL 高性能异步通讯库,训练任务吞吐相比其他开源框架有 1.2x-3.5x 的提升;
提供了更友好、灵活的流水线支持,降低了模型开发迭代所需要的人力;
可在 GPU上高效地支持数十亿至上千亿参数量的大模型;
对带宽要求低,在私有化部署无 RDMA 强依赖。
V100 测试:每个机器 8 张 Tesla V100 32G 型号 GPU,网络带宽 100G A100 测试:每个机器 8 张 Ampere A100 40G 型号 GPU,网络带宽 800G
模型:GPT-13B Megatron:v2.4,tensor-model-parallel-size 设置为 4, pipeline-model-parallel-size 设置为 4 DeepSpeed:v0.4.2,使用 DeepSpeedExamples 开源社区中默认的 zero3 的配置 运行环境 V100/TCP :100Gb/s TCP 网络带宽,4 机,每机 8 张 Tesla V100 32G GPU V100/RDMA:100Gb/s RDMA 网络带宽,4 机,每机 8 张 Tesla V100 32G GPU A100/TCP:800Gb/s TCP 网络带宽,4 机,每机 8 张 Tesla A100 40G GPU A100/RDMA:800Gb/s RDMA 网络带宽,4 机,每机 8 张 Tesla A100 40G GPU 统计值:Throughtput (samples/s)
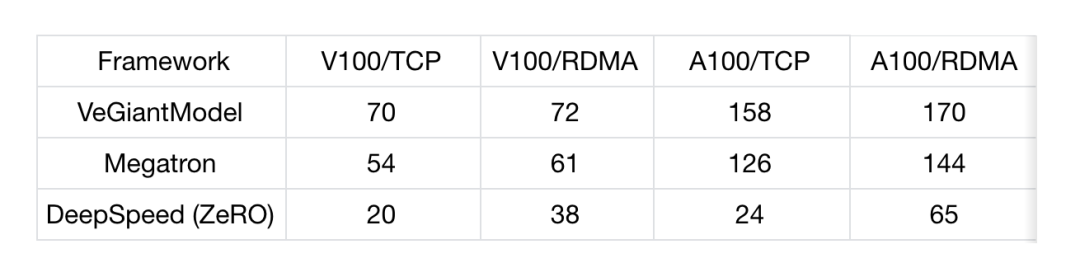
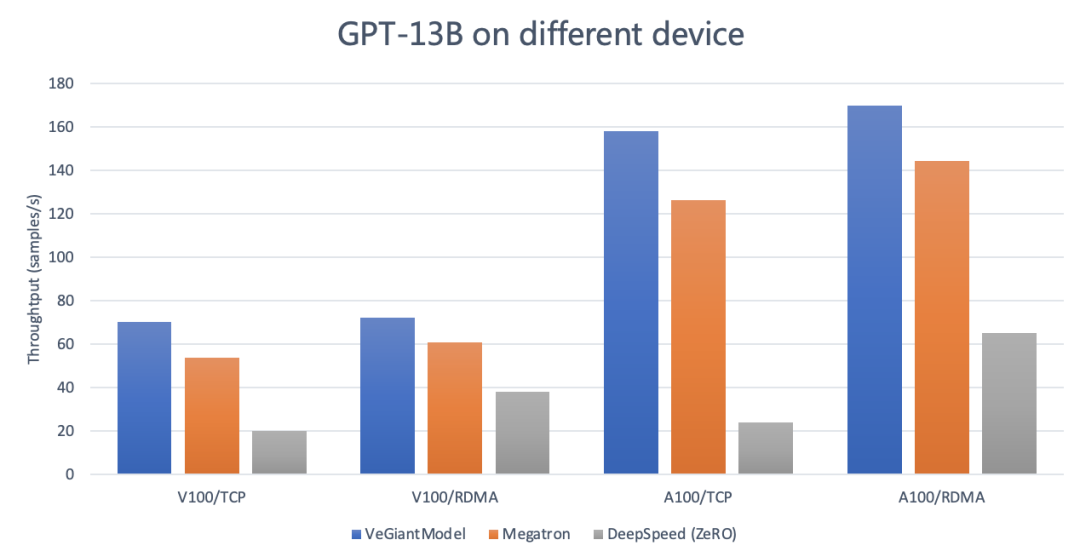
veGiantModel 性能更优:无论是在高带宽还是低带宽的场下,veGiantModel 在 V100 和 A100 上均胜出 Megatron 和 DeepSpeed,最高可达 6.9 倍提升。 veGiantModel 对网络带宽要求低:veGiantModel 在带宽变化对吞吐的影响相对最小 (<10%),而 DeepSpeed(ZeRO) 是对带宽要求最高的,最高可达将近 5 倍的差距。
ByteCCL (BytePS) 高性能异步通讯库。 支持定制化的并行策略,可以将性能优化推到极致。 在支持数据并行、算子切分、流水线并行 3 种分布式并行策略时,veGiantModel 会综合考虑到跨机的带宽,自动调整 toplogy 的 placement。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接







排名
热点
搜索指数
- 1 习近平同马克龙交流互动的经典瞬间 7904376
- 2 黑龙江水库冰面下现13匹冰冻马 7807878
- 3 微信表情包戒烟再度翻红 7711972
- 4 2025你的消费习惯“更新”了吗 7617144
- 5 三星堆与秦始皇帝陵竟有联系 7522386
- 6 为啥今年流感如此厉害 7424354
- 7 劲酒如何成了年轻女性的神仙水 7330946
- 8 首次!台湾浅滩海域搜救应急演练举行 7238659
- 9 你以为的进口尖货 其实早已国产了 7143317
- 10 中疾控流感防治七问七答 7042200