北京大学DAIR实验室、腾讯机器学习平台部Angel Graph团队
来自北京大学 DAIR 实验室与腾讯机器学习平台部 Angel Graph 团队共同完成的研究斩获WWW 2022 唯一最佳学生论文奖(Best Student Paper Award)。
4 月 29 日晚,国际万维网顶会 WWW-2022(The Web Conference,简称 WWW)公布了本届会议的最佳论文。以北京大学计算机学院崔斌教授博士生张文涛为第一作者的论文 《可扩展的图神经结构搜索系统 (PaSca: a Graph Neural Architecture Search System under the Scalable Paradigm)?》斩获大会唯一的最佳学生论文奖(Best Student Paper Award)。
WWW(现改名为 TheWebConf)会议是计算机和互联网领域历史最为悠久同时最为权威的顶级学术会议之一,被中国计算机学会列为 A 类推荐国际学术会议。本次会议共收到 1822 篇论文投稿,最终录用 323 篇,录用率为 17.7%。本次会议仅评选出一篇最佳论文奖和一篇最佳学生论文奖,获奖论文首先被会议 “系统和基础设施” 方向推荐为最佳论文进入到大会最佳论文候选(共 11 篇),并在最终评比中获最佳学生论文奖。获奖论文是北京大学 DAIR 实验室与腾讯机器学习平台部 Angel Graph 团队共同完成,这是 WWW 成立 30 多年以来,中国学术研究机构第 2 次获得最佳学生论文奖。
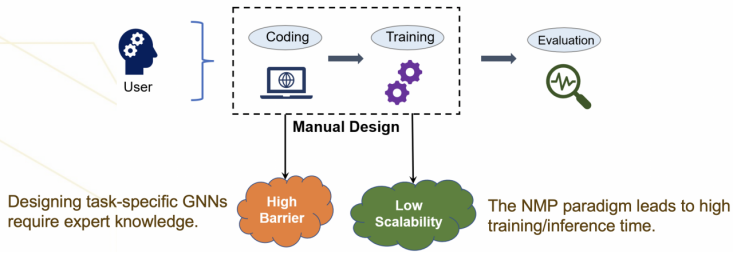
图神经网络模型在多个图任务上都取得了最佳效果,并受到了学术界和工业界的广泛关注。然而,现有的图神经网络系统有如下图所示的两个瓶颈。一方面,受限于单机场景下的存储和计算开销以及分布式场景下的通信开销,大多数基于消息传播机制 (Neural Message Passing,NMP) 的图神经网络模型可扩展性较低,很难直接用于现实生活中的大规模图数据。如图 2 所示,以典型的基于消息传播机制的 GraphSAGE 模型为例,分布式场景下的高昂通讯代价限制了图神经网络的可扩展性。此外,如图 3 所示,现有的图神经网络系统需要用户针对特定图数据和图任务编写代码和训练流程,然而设计网络结构也需要经验丰富的专家,建模成本很高。
本论文研究了大规模图学习过程中面临的图模型可扩展性低以及建模门槛高两个问题,进而提出了一套能自动化建模超大规模图网络的可扩展图学习系统。具体来说,本文提出了一个新颖的图神经网络建模范式,并基于该范式设计了一个超过 15 万种网络结构的可扩展图网络设计空间,为图神经网络可扩展性的相关研究指明了一个新的方向和路线。此外,本文还实现并开源了一套多目标(如模型预测效果和资源占用)自动化图神经结构搜索系统,来支持更简单和更高效的大规模图学习。区别于现有的大规模图神经网络系统,本文提出的 PaSca 是一个端到端的系统。如图 4 所示,系统的输入有两部分组成:1)图数据 2)搜索目标(预测性能、内存占用、训练以及预测效率等)。给定这两个输入,系统能自动化地在预定义的可扩展图网络搜索空间进行高效地搜索,并输出能兼容多个搜索目标的可扩展图神经网络模型。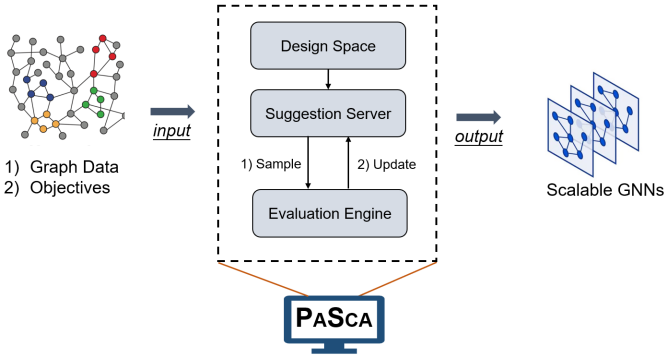
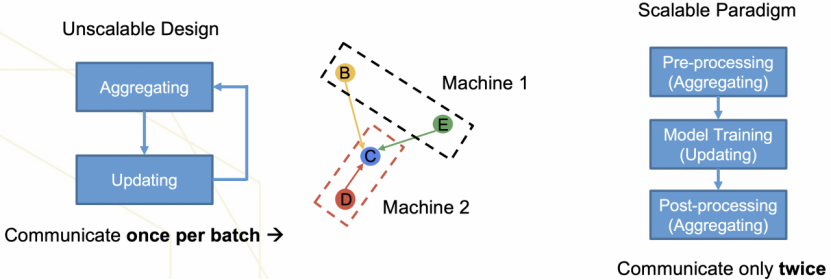
如图 5 所示,现有的图神经网络模型大都遵循如上图所示的消息传递机制。此外,为了兼容主流的图神经网络模型,相应的图神经网络系统也使用基于消息传递机制的系统抽象。然而,基于消息传播机制的图模型在每个 batch 训练过程中都需要进行聚合和更新操作。当图节点数据分布在不同机器上时,频繁的聚合操作会导致高昂的通信开销。区别于现有的消息传递机制,本文提出的 Scalable Paradigm(SGAP)将消息聚合操作和更新操作分离,定义了可扩展性图神经网络建模的新范式:前处理—训练—后处理,消息聚合操作只存在于前处理和后处理中,极大地降低了分布式场景下的通信开销。本文提出的自动化搜索系统包含两个模板,分别是搜索引擎以及分布式验证引擎。如图 6 所示,在每一次迭代中,搜索引擎都会从搜索空间中推荐相应的可扩展图神经网络结构,之后评估引擎训练图网络模型并返回模型的验证结果。
搜索引擎的主要目标是找到在 SGAP 建模范式下能同时兼容多个搜索目标的可扩展图神经网络结构。如表 1 所示,它首先定义了一个包含 15 万种不同网络结构的搜索空间,并基于贝叶斯优化来实现网络结构的推荐。在每次迭代中,推荐服务器会建模观测到的网络结构与优化目标值之间的关系,并推荐能最好地平衡多个优化目标的网络结构。最后,它基于验证引擎返回的观测结果来更新历史信息。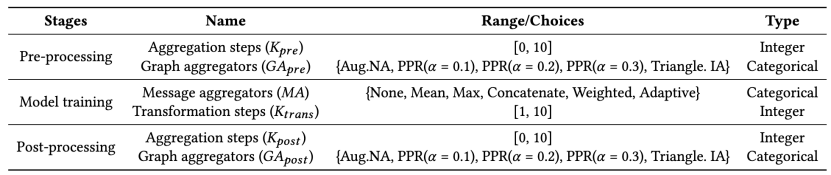
验证引擎的主要是用来高效评估被推荐的模型性能。对于前处理和后处理阶段,图数据聚合器会将图数据划分并存储到多台机器上。对于任意节点,当它的第 i - 阶消息计算完成之后,工作节点会拉取它的邻居信息并计算它下一阶的信息。在训练阶段,每个工作节点都可以用批训练的方式基于参数服务器来实现网络参数的更新。本文在十个真实的数据集上进行实验,实验主要是为了说明:1)基于 SGAP 的图神经网络建模范式具有高可扩展性;2)PaSca 系统搜索出来的网络能很好地平衡多个搜索目标,并取得良好的预测性能。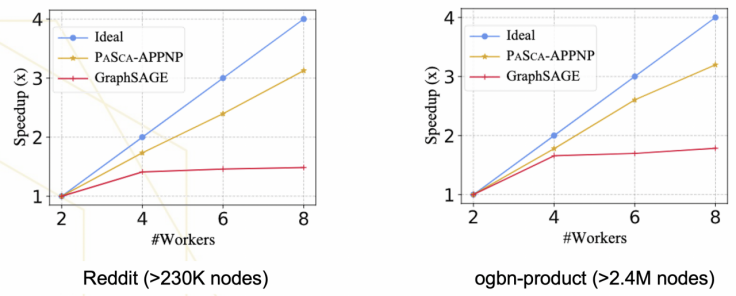
本文比较了基于 SGAP 范式建模的 PaSca-APPNP 模型以及基于 NMP 范式建模的 GraphSAGE 模型在分布式场景下的可扩展性。固定总的批处理大小并增加工作节点的数目,如图 7 所示,实验发现 PaSca-APPNP 能够获得更接近理想情况下的加速比。
如图 8 所示,实验展示了 PaSca 系统在 Cora 数据集的搜索结果的帕累托平面。本文从中挑选了 3 个代表性的模型,分别命名为 PaSca-V1, PaSca-V2 和 PaSca-V3。这些代表性模型能兼容不同的优化目标,比如 PaSca-V3 取得了最小的分类误差但是比 PaSca-V2 的预测时间更久。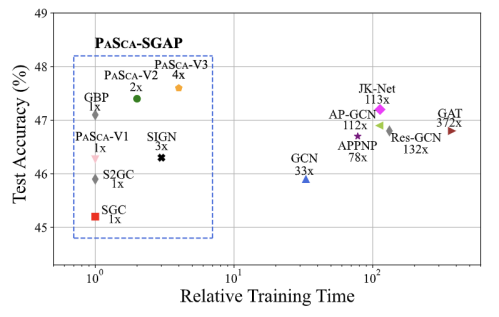
如图 9 所示,本文实验测试了搜索出来的代表性模型在实际 Industry 数据集上的预测性能和训练时间。可以看到 PaSca-V2 和 PaSca-V3 的预测效果都优于 JK-Net,但是训练时间更短。此外,如表 2 所示,本文在八个数据集上测试搜索出来的代表性模型的预测性能。实验发现,基于 SGAP 建模范式的图神经网络模型能够取得和其他范式下模型相当甚至更好的预测性能。另外,搜索出来的 PaSca-V3 始终取得了最好的模型预测性能。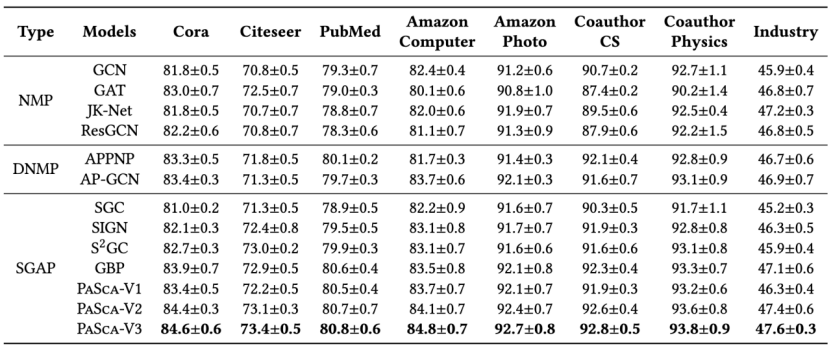
Angel Graph 图计算团队目前负责论文成果在腾讯内部的技术落地。获奖论文的相关成果已实现于 Angel Graph 系统并部署于腾讯公司太极机器学习平台,广泛应用于金融风控和社交网络推荐等业务,代表性业务落地场景如下:1)微信公众号文章视频推荐场景点击率提升 1.6% 2)PCG 平台与内容事业群内容风控场景恶意识别覆盖率提升 10% 3)微信运营平台中心社交反欺诈场景欺诈账号识别覆盖率提升 20% 4)全民 K 歌个人主页用户相似推荐场景人均关注提升 2.397%。图神经网络模型在多个图任务上都取得了最佳效果,并受到了学术界和工业界的广泛关注。然而,大多数图神经网络模型可扩展性较低,很难直接用于现实生活中的大规模图数据。此外,设计针对特定图数据和图任务的神经网络结构也需要经验丰富的专家,建模成本很高。为此,本文提出了一个非常新颖的图神经网络建模范式,并基于该范式设计了一个可扩展的图神经结构搜索空间,为图神经网络可扩展性的相关研究指明了一个新的方向和路线。此外,本文还实现并开源了一套多目标(如模型预测效果和资源占用)自动化图神经结构搜索系统,搜索出来的代表性模型在预测性能、效率以及可扩展性方面都取得了较好的平衡。PaSca 系统能帮助研究者更好地探索可扩展的图神经网络结构,极大地促进了图神经网络从学术研究走向实际落地。
??THE END?
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号





